fit 2002 >
Gruppenthema >
Entstehungskontext
Überblick
Die Anfänge der Datenbanken und den darauf aufbauenden Strukturen
des Datamining und Datawarehousing waren in den frühen 60er. Hier
wurden die Daten noch auf Medien wie Magnetbändern abgelegt, die
nur eine schlechte Zugriffsmöglichkeit aufweisen. Ausserdem wurden
für jedes Programm eine eigene redundante "Datenbank" (meist
nur als Textfiles ohne oder mit Struktur abgespeichert) erstellt.
In den 60er Jahren entwickelte sich die DSS ("decision
support systems") aus denen sich dann auch der Bereich des Datawarehouse
entwickelte. Bis ca. zur Mitte der 60er Jahre bestand die Welt der DSS
aus sogennanten "master files", die die Daten auf Magnetbändern
enthielten. Für jede Anwendung wurden eigene Programme geschrieben,
die die Reports für die Daten lieferten
Anfang der 70er kam es dann jedoch zur Entwicklung des sogennaten "direct
access storage device (DASD) - darunter fallen alle heute üblichen
Speichermedien: HDD, CD-ROM, usw.
. Diese neue Art der Datenspeicherung öffnete die Tür zu neuartigen
Systemen, wie den DBMS ("database management systems"), oder
Kontrollsystemen zur Überwachung von Daten, usw).
Gegen Ende der 80er Jahre entstand dann das Gebiet Datamining als eine
Disziplin in der Informatik mit Bezügen zur Logik, Künstlichen
Intelligenz und Statistik. Das Wort Datamining steht für "Database
mining", dem Ausbeuten von Datenbanken nach wertvollen Informationen.
Diese Disziplin steht im engen Zusammenhang zu den Methoden im Bereich
des Datawarehouse.
Zu dieser zeit wurde auch ein neues Programm immer populärer: das
"extract" - Programm. Diese Anwendung durchforstet Dateien,
extrahiert Daten nach bestimmten Kriterien und speichert diese Daten an
einem anderen Ort. Wegen der verbesserten Performance und Datenkontrolle
erhielten diese Programme eine große Akzeptanz unter den Firmen.
Diese "extract" Programme extrahieren die Daten jedoch nicht
nur aus einer einzelnen Datenbasis, sondern auch aus Resultaten eines
anderen extract-Prozesses. Dies führte in Unternehmen schliesslich
zu den "spiderwebs" (siehe Abbildung 1 aus W. Inmons "Building the Datawarehouse").
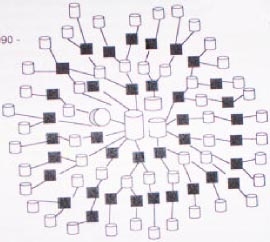
(Abbildung 1)
Spiderwebs führten jedoch zu einer Reihe von Problemen:
· Glaubwürdigkeit der Daten (da die Daten oft mehrmals abgespeichert
werden, mit verschiedenen Zuständen, kann es zu unterschiedlichen
Ergebnissen kommen)
· Produktivität (oft lange Suche nach Daten)
· Daten, aber keine Informationen (durch hin- und herkopieren der
Daten ist es nicht möglich sie wieder auf eine einzige Datenbasis
zu reduzieren)
Heute gibt es die bekannten Datenbanksysteme. Hier gibt es eine klare
Trennung zwischen Programmen und Daten.
Vorteile:
· logische Datenunabhängigkeit (von deren Darstellung)
· wenig Redundanz
· Integritätsbedingungen leicht prüfbar/haltbar
· Zugriffsschutz
· flexibler Gebrauch der Daten
>Information Retrieval
>Requirement
Engineering
>Knowledge Engineering
Weiterführende Informationen
> Hans Wilhelm Wieczorrek Peter Mertens; Data X Strategien; Springer,
Germany, 1999.
> Mathias F. H. Hahn; Algorithmen
für Data Mining; 2001
> W. H. Janko, P. Bruhn, S. Koch, M. Hahsler; Data
Mining, Umfeld, Prozeß, Methoden 2000
>Vivek Gupta. An Introduction to Data Warehousing, 2002. system-services.com/dvintro.asp
>Walter Immons. Building the Data Warehouse. John Wiley & Sons,
Inc, 1992
>Dr Rudolf Munz Jo Bager, Jörg Becker, 1997, c't 3/97
>Prof. Bernd Breutmann, "IT-Kompaktkurs Datenbanken"www.fh-deggendorf.de/doku/fh/meile/bachelor/lehre/db/f12/skript12.pdf
www.fh-deggendorf.de/doku/fh/meile/bachelor/lehre/db/f13/skript13.pdf
Verweise auf Arbeiten anderer gruppen
>linklink blabla
>Entstehungskontext | Konzepte und Techniken | Entwicklung und Auswirkungen | Praxis | Bewertung