fit 2002 > Wissensakquisition
> Konzepte und Techniken > Datamining
Überblick
Konzepte und Techniken
Voraussetzungen
Eine Bedingung für den erfolgreichen Einsatz von Data Mining Werkzeugen ist die Bereitstellung einer "konsistenten, qualitativ hochwertigen Datenbasis". Diese kann am sinnvollsten durch ein Data Warehouse zur Verfügung gestellt werden.
Ablauf
Ansprüche an die Daten
Die Eingabedaten stammen meist aus einer Datenbank. Hier können technische
Probleme durch die Art der Speicherung auftreten und Schwierigkeiten im
Zusammenhang mit der Unvollkommenheit der Daten.
Auf folgende Eigenarten von Daten in Realdatenbanken muss man beim Datamining
achten:
- Unvollständigkeit der Daten
Datenbanken sind in aller Regel nicht mit Blick auf das Data Mining konstruiert und gefüllt. Deshalb gibt es das Problem, dass trotz riesiger Datenmengen wichtige Informationen fehlen oder zumindest unterrepräsentiert sind. - Fehlerhafte Daten
In der Praxis sind häufig per Hand zusammengestellte Datensammlungen anzutreffen. Dies verschärft das ohnehin große Problem falscher oder fehlerhafter Daten, die zudem meist besonders auffällige Muster produzieren. Mit dem Problem, falsche Dateneingaben aufzufinden und zu korrigieren, beschäftigt sich eine eigene Kategorie von Data-Mining-Systemen. Daten zu reinigen ist jedoch nicht unproblematisch. Häufig erweisen sich scheinbare Anomalien oder Ausreißer als wesentliche Hinweise auf interessante Fakten oder Entwicklungen. - Redundanz
Ein besonderes Problem stellen Redundanzen dar. Diese doppelten Daten würde das System unnötigerweise als neues Wissen extrahieren. Dies prägt eventuell falsche Muster oder verstärkt Trends, die nicht wirklich relevant sind.
In diesem Zusammenhang sind auch mehrfache Eintragungen von Daten zu sehen, die sich zwar auf die gleiche Information beziehen können, aber trotzdem mehrfach Relevanz erlangen. (z.B. das Maier - Meier Namens Problem). - Irrelevante Felder
In Realdatenbeständen sind zahlreiche überflüssige Felder für die Datenmustererkennung. Leider ist oftmals nicht bekannt, auf welche Felder man ohne Informationsverlust verzichten kann. - Große Datenmengen
Die riesigen Datenbestände realer Datenbanken verhindert es häufig, Algorithmen zu verwenden, die in kleineren Datensammlungen gute Ergebnisse liefern, da sie in größeren zuviel Zeit benötigen oder nicht mehr berechenbar sind. - Dynamik der Daten
Charakteristisch für Datenbestände ist, dass sie sich laufend ändern. In Data-Mining-Systemen, die online arbeiten (d.h. während der Benutzung eingesetzt werden), muss darauf geachtet werden, dass die Änderungen nicht zu falschen Ergebnissen führen.
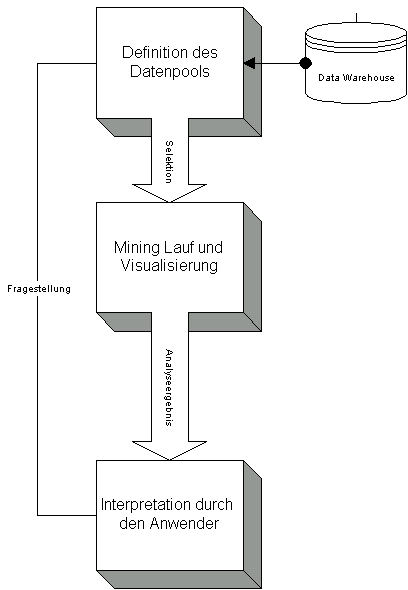
Der eigentliche Ablauf
[Quelle DM Seminar]
Definition des Datenpools
Der größte Anteil am Gesamtaufwand eines Mining-Projekts entsteht immer bei der Zusammenstellung und der Aufbereitung der Daten. Die Datenextraktion aus verschiedenen Tabellen, Bereinigungen und Kategorisierungen ist sehr zeitintensiv und sie erfordert neben technischen Fertigkeiten vor allem fachliches Know-how.
Fehler an dieser Stelle verzögern Projekte sehr stark und schon die
Hineinnahme
oder das Weglassen weniger Datenattribute kann über Erfolg und Misserfolg
entscheiden.
In dieses Projektphase zahlt sich Erfahrung besonders stark aus. Bei einem sehr
großen Datenbestand reicht es schon oft aus nur eine Stichprobe zu verwenden.
Der Data-Mining Lauf und die Visualisierung
Die Laufzeit der Dataminingberechnungen bewegen sich in
einem Zeitrahmen von wenigen Sekunden bis hin zu vielen Stunden.
Die Form der Visualisierung ist meist softwareproduktabhängig und kann nur wenig beeinflusst werden.
Gerade die Visualisierung ist ein wichtiges Qualitätsmerkmal der verwendeten
Software. Als einzige
Schnittstelle zum Menschen fällt der Visualisierung nämlich die Aufgabe
zu, die relativ komplexen Sachverhalte dem Anwender wirklich verständlich
darzustellen. Eine gute Darstellung sollte alle wesentlichen Zusammenhänge klar
herausstellen und unnötigen Ballast vermeiden.
Interpretation durch den Anwender
Letztlich obliegt es dem Anwender selbst die nichttriviale Zusammenhänge als solche zu erkennen und sie von den trivialen zu trennen. Danach kann er dann die wirklich wertvollen Teilergebnisse näher untersuchen. Hierzu kann er zum Beispiel einen erneuten Durchgang starten um die Ergebnisse zu verbessern.
Methoden und Techniken
Klassifikation
Aufgabe der Klassifikation ist eine Zuordnung der betrachteten Objekte zu
bestimmten Klassen. Die Zuordnung findet auf Grund von Entscheidungsregeln an,
die auf die auf gewisse Objektmerkmale angewandt werden.
Beispiel:
Ein Kreditinstitut ist daran interessiert, die
Kreditwürdigkeit eines neuen Kunden ermitteln zu können. Anhand
der Einstufungen der bisherigen Kunden und der mittels Data
Mining
ermittelten Aussagen kann man nun über neue Kreditanträge
entscheiden.
Bekannteste Methode dieses Verfahrens ist die Entscheidungsbaummethode, weitere Methoden das Fallbasierte Schließen oder Neuronale Netze.
Entscheidungsbaummethode (Decission Tree)
Die Struktur eines Entscheidungsbaumes wird in der nachfolgenden Abbildung gezeigt. Dabei sei angenommen, dass die Daten verschiedene Werte im Zielattribut besitzen, d.h. nicht nur ein einzelner Wert (z.B. Kunde=Ja) auftritt.
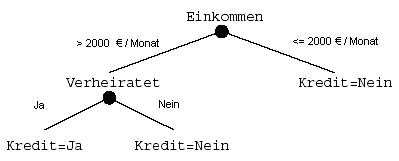
Durch diese Technik können automatische Entscheidungen für ähnliche
Situationen und Problemstellungen in der Zukunft gemacht werden.
Der Aufbau des Baumes erfolgt anhand der vorhanden,
historischen Daten. Aufgrund der meist schon vorhanden Einteilung der Daten in
Klassen werden weitere Untergruppen gebildet. Nun wird versucht an jeder
Verzweigung die bestmöglichste Frage zu stellen. Aus Gründen der
Wirtschaftlichkeit und Effektivität wird der Baum nicht bis ins letzte Detail
modelliert, sondern nur solange unterteilt und weitergeführt, bis eine der drei
folgenden Bedingungen erfüllt ist:
- Die Segmente enthalten nur einen Eintrag oder eine minimale algorithmisch definierte Anzahl von Einträgen.
- Das Segment ist vollständig organisiert mit genau einem Prognose Vorhersagewert.
- Die Verbesserung in der Struktur der Daten ist nicht ausreichend genug um eine neue Unterteilung zu rechtfertigen.
Fallbasiertes Schließen
Um einen neues Problem zu lösen, wird in der Falldatenbasis (Erinnerung)
nach früheren Fällen gesucht, bei denen ähnliche Probleme zu behandeln waren.
Deren Lösung wird auf das aktuelle Problem übertragen.
Das kann, muss aber nicht erfolgreich sein. Nach Abschluss der Problemlösung ist
ein neuer Fall behandelt worden, der wiederum in die Falldatenbasis aufgenommen
werden kann.
Damit sind fallbasierte Systeme lernfähig und sehr flexibel, im Gegensatz etwa
zu regelbasierten Systemen.
Neuronale Netze
Mit neuronalen Netzen versucht man die Vorgänge im menschlichen Gehirn nachzubilden. Das Wissen zur Lösung einer Aufgabe wird in den Neuronen (den Knoten) eines Netzes abgelegt, zwischen denen dann Verbindungen hergestellt werden. Die Knoten entsprechen dabei einem Neuron des menschlichen Gehirns, die Kanten stellen Verbindungen zwischen Neuronen im menschlichen Gehirn dar. Es ist dem Entscheidungsbaumverfahren sehr ähnlich allerdings erweitert es seine Parameter selbstständig, um genauere Schlüsse zu ziehen.
Um ein neuronales Netzwerk sinnvoll verwenden zu können, muss zuerst die Aufgabenstellung anhand von Beispielen trainiert werden. Das Lernen des nötigen Basiswissens wird durch die Angabe von Eingangsmengen und den zu berechnenden Ausgangsmengen erreicht. (zum Beispiel durch Erlernen von bereits verifizierten Beispielen aus der Vergangenheit).
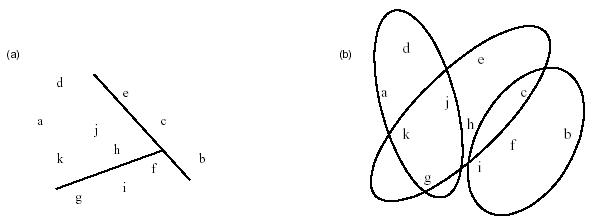
Segmentation
Unter Segmentierung versteht man die Zerlegung (Partitionierung) einer Datenbasis in einzelne Segmente, die aus jeweils zueinander ähnlichen Datensätzen bestehen. Im Prinzip bedeutet das nichts anderes, als daß diese Datensätze Attribute enthalten, deren jeweilige Ausprägungen zu einem gewissen Grad ähnlich sind, womit Objekte in Gruppen zusammengefasst werden, die vorher nicht bekannt waren.
Sichtbar können solche Zusammenhänge mit Semantischen Netzen gemacht werden, die Suche nach den Zusammenhängen werden mit der Clusteranalyse durchgeführt
Clusteranalyse
Ziel ist es, Strukturen in Daten zu erkennen, also transparente und wissensbasierte Repräsentationen der in Datensätzen inhärent enthaltenen Information zu lernen. Dabei wird von den Rohdaten aus nach noch nicht bekannten Zusammenhängen gesucht. Dies geschieht meist als erster Schritt in sehr großen Datenbeständen, um erste Daten mit ähnlichen Eigenschaften zu sichten, die darauf mittels anderer Techniken weiter untersucht werden.
[Quelle DM Seminar]
Prognose
Dient zur Vorhersage von unbekannten Merkmalswerten auf der Basis anderer Werte zumeist aus früheren Perioden. Ziel ist es, eine Vorhersage für die Zukunft zu treffen. Die Techniken sind zumeist statistischer Natur. Zeitreihenanalysen zum Beispiel ermöglichen so eine Vorhersage auf der Grundlage interpretierbarer Muster aus der Vergangenheit. Auch zählen Entscheidungsbäume zu den Prognose Methoden des Data Mining.
Abhängigskeitsanalyse
Beziehungen zwischen verschiedenen Merkmalen eines Objektes. Diese Beziehungen können zu einem bestimmten Zeitpunkt erreignen, oder über eine Periode manifestieren. Die Warenkorbanalyse ist das bekanntestes Beispiel. Auch können Verfahren wie Informationsflußgraphen zu dieser Methode gezählt werden.
Warenkorbanalyse
Dabei werden Gruppen von häufig gemeinsam verkauften Produkten aufgefunden. Sie kommt fast ausschließlich im Einzelhandel zur Anwendung und stellt hier die beste Möglichkeit bereit, das Kaufverhalten zu analysieren. Die Ergebnisse können dazu dienen, die einzelnen Produkte gemäß ihrer Gruppenzugehörikeit in den Regalen aufzustellen. Ist es möglich, die Warenkorbanalyse mit Kundendaten zu verknüpfen, können Kaufwahrscheinlichkeiten für zukünftige Einkäufe errechnet werden. Außerdem kann man dadurch leicht kundenspezifische Werbung anbieten.
Informationsflußgraphen
Dient zur Analyse von Beziehungen zwischen den Datensätzen. Diese Methode versucht Beziehungen zwischen den einzelnen Datensätzen herzustellen. Meistens wird diese Methode benutzt um Marketingaktionen besser auf einzelne Kunden abstimmen zu können.
Abweichungsanalyse
Bei obigen Aufgaben geht es darum Regelmäßigkeiten aufzufinden. Dies dient der Findung von Objekten, die der Regelmäßigkeit der meisten anderen Objekte nicht folgt. Bei diesen ,,Ausreißern" kann es sich um fehlerfreie und interessante Merkmalsausprägungen handeln oder aber um falsche Daten. Die Zielsetzung der Abweichungsanalyse besteht darin, die Ursachen für die untypischen Merkmalsausprägungen des Ausreißers aufzudecken. Wird ein Ausreißer im Datenbestand identifiziert, so durchsucht das DM Tool alle assoziierten Datenbestände, um zu klären was darauf Einfluss genommen hat und zu einer abweichenden Merkmalsausprägung geführt habt. Handelt es sich bei einem Ausreißer um einen fehlerhaften Wert, wird dieser aus dem Datenbestand gelöscht. Da auf diese Weise die Datenqualität gesteigert wird, werden Methoden zur Abweichungsanalyse oft in der Phase der Vorverarbeitung benutzt.
Sonstige Algorithmen
Zwei wichtige, nicht eindeutig in die obige Klassifizierung einzuordbare Algorithmen sind die genetischen Algorithmen und die "Nearest-Neighbor Methode".
Genetische Algorithmen
Dies sind Optimierungstechniken, die Prozesse benutzen, so wie genetische Kombination, Mutuation und natürliche Selektion in einem auf Evolution basierten Konzept.
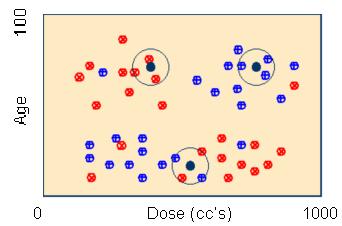
Nearest neighbor Methode
Dies ist ein Klassifizierungsverfahren, bei dem für einen neuen Datensatz die Entfernung zu allen bekannten Datensätzen berechnet wird und die k nähesten - bestimmen die Klasse. Dafür ist natürlich die Auswahl einer geeigneten Abstandfunktion wesentlich.
[Quelle DM Seminar]
- benutzt die gesamte Datenbank als Modell
- finde den naheliegensten Datenpunkt und mache das selbe wie für den vorigen
- leicht zu Implementieren
- Nachteil: riesige Modelle
Weiterführende Informationen
Algorithmen in DM
>[ http://www.numerik.uni-kiel.de/~mha/Algorithmen4DM.pdf]
DM in Machine Learning
>[ http://www.informatik.uni-rostock.de/mosi/Vorlesung/Folien/DM0102/introduction01.pdf]
DM Forum
>[http://www.database-marketing.de/mininghome.htm]
Data Mining
>[http://www.biz.uiowa.edu/class/6k220_park/OldStudProjects/F97/group10/Brief_history.htm]
An Introduction to Data Mining
>[http://www3.shore.net/%7Ekht/text/dmwhite/dmwhite.htm]
DIMACSWorkshop on Data Mining in the Internet Age
>[ http://dimacs.rutgers.edu/Workshops/DataMining/abstracts.html]
Glossary of Data Mining
>[http://www3.shore.net/%7Ekht/glossary.htm]
Datamining Seminar
>[wwwai.wu-wien.ac.at/~koch/lehre/inf-sem-ws-00/
nentwich/mining.pdf ]
Verweise auf Arbeiten anderer Gruppen
Data Mining
>[http://cartoon.iguw.tuwien.ac.at:16080/fit/fit08/team5/welcome.html]
>Entstehungskontext | Konzepte und Techniken | Entwicklung und Auswirkungen | Praxis | Bewertung