fit 2002 >
Intelligente Agenten > konzeptionelle
Entwicklungen und Auswirkungen
Überblick
Allgemeine Entwicklungen und Auswirkungen
Hierzu noch einmal ein Wort zu den Aufgaben eines Intelligenten Agenten.
Um seine Aufgaben korrekt und ordnungsgemäß zu erfüllen, benötigt ein intelligenter Agent
gewisse Funktionen, um die ihm gestellten Aufgaben oder einzelne Aufgabe zu erfüllen. Zum
Beispiel sollte ein Internet-Suchagent fähig sein, überhaupt Zugang zum Internet zu erhalten.
Ein Agent muss stets mit dem Umfeld interagieren, sein Umfeld mit Hilfe von Sensoren zu erfassen
und dementsprechend auf sein Umfeld zu reagieren.
Aufgabenbereich Wissen
Jeder Agent hat quasi sein eigenes Gedächtnis, in dem er Wichtigstes und Nötigstes abspeichert,
wie die Aufgaben und Ziele seiner Mission; oder auch die von ihm verwendeten Algorithmen zur
Erfüllung seiner Aufgabe. [GRE]
Bei den in den Agenten verwendeten Wissensrepräsentationen und Techniken handelt es sich um die
Wissensrepräsentationen und Techniken der künstlichen Intelligenz. Beim Wissen können zwei Arten
unterschieden werden, das von vornherein vorhandene "a-priori Wissen" und vom Agenten selbst
"erlerntes Wissen". Ein Agent kann selbstverständlich beide Arten von Wissen in sich tragen.
A-priori Wissen: Beim a-priori Wissen handelt es sich um Wissen, welches entweder vom
Entwickler, vom Benutzer oder vom umgebenden System vorgegeben wird.
Der Entwickler hat die Möglichkeit, Wissen in vielen verschiedenen Formen dem Agenten einzuprägen,
z.B in Form eines Neuronalen Netzes, welches vor dem Einsatz vom Entwickler trainiert wurde oder
auch in Form einer Suchstrategie. Es stehen dafür sämtliche Techniken der künstlichen Intelligenz
und der Wissensrepräsentation zur Verfügung.
Wenn der Benutzer Wissen vorgibt, handelt es sich dabei meist um vom Benutzer selbst definierte
einfache Regeln. Als Exempel kann man die automatische Filterung von Spam-Mails in ein gewisses
Verzeichnis anführen, wenn dem Mail eine bestimmte Art von Absender oder Betreff-Zeile gegeben
wurde. Oftmals stellt der E-Mail-Client die nötigen Filterdialoge und Eigenschaften zur Verfügung.
Zuguterletzt kann Wissen noch vom umgebenden System vorgegeben werden. Hier wird z.B. das Wissen
um die Ansprechpartner in einer Netzwerkumgebung verstanden. Dazu zählt auch das Wissen, welche
Dienste der Agent von anderen beziehen kann oder welche Datenbanken zur Verfügung stehen.
Erlerntes Wissen: Lernende Agenten nehmen nicht nur die Umgebung wahr, sondern - wie der
Name bereits sagt - versuchen, darauf zu reagieren und aus diesen Reaktionen zu lernen und alles
Beobachtete auszuwerten. Schließlich kann mit den neuen Erfahrungen und dem neuen Wissen auf die
Umwelt angepasst reagiert werden, damit gewisse Abläufe besser regeln, nahezu optimieren und
auch zu automatisieren.
Vielleicht kann man als ein gutes Beispiel Internet-Suchmaschinen aufführen. Diese lernen aus
der Umwelt, indem sie schon auf viele Fragen - je nach Beobachtungen im Internet - bereits die
richtigen Antworten parat haben und somit den Benutzer längere Wartezeiten zu ersparen.
Aufgabenbereich Kommunikationsfähigkeit
Kommunikationsfähig sollte der Intelligente Agent einerseits mit dem Anwender über eine
Schnittstelle sein, andererseits ist es auch von Wichtigkeit, mit anderen Agenten und Systemen
zusammenzuarbeiten und Datenaustausch zu betreiben (siehe Multiagentensysteme).
Die Benutzerschnittstelle stellt im Großen und Ganzen ein Interface mit den gewohnte
Eingabeobjekten (Buttons, Eingabefelder, ...) dar. Nun gibt es auch immer die Möglichkeit,
alles zu übertreiben, viel Sound und Multimedia in einen Agenten hineinzustecken, gar
Sprachausgabe, um ihn eine echte Persönlichkeit zu geben.
Bei Multiagentensystemen funktioniert die Kommunikation nun nicht mehr über gewisse
User-Interfaces, jetzt müssen schon speziellere Sprachen für den erfolgreichen Datenaustausch
vorhanden sein. Hier stellt sich natürlich immer die Frage nach der Norm, welche nicht
vorhanden ist, es gibt genug verschiedene Sprachen, die eine Inkompatibilität erfolgreich
bestätigen: TeleScript, SmallTalkAgents, Agent Tcl (Tool Command Language), Knowledge Query
and Manipulation Language (KQML) oder Knowledge Interface Format (KIF).
Hierfür hat sich eine Organisation, nämlich die "Advanced Research Projects Agency"
(ARPA), angenommen, um mit dem "Knowledge Sharing Effort" (KSE) - Projekt dieser
Entwicklung entgegen zu wirken. KSE beschäftigt sich mit der Entwicklung von Vereinbarungen,
welche es erlauben, verteilte Wissensbasen oder Wissensbasierte Systeme zu gestalten. Das Ziel
ist, die Definition, die Entwicklung, und das Testen von Systemen, die es den Entwicklern
erlauben, größere und umfangreichere Systeme zu verwirklichen, als es mit Einzelsystemen
möglich wäre.
Anwendungsgebiete Intelligenter Agenten
Der Einsatz intelligenter Agenten ist in vielen Bereichen nützlich. Wichtige Anwendungsgebiete
wären laut [IC2] folgende:
- Mobile Computer: Personal Digital Assistants (PDA) sind in der Lage, selbstständig Aufgaben
für den Anwender auszufüren, ohne dass dieser ständig mit dem Netz verbunden sein muß. Z.B. ist
er in der Lage, E-Mails zu empfangen oder nach jeglicher Informationen zu suchen.
- System- und Netzmanagement: Intelligente Agenten sollten den Systemadministratoren helfen,
Fehler und viele Ungereimtheiten zu erkennen, diese aufzuspüren und zu beheben. Sie
überwachen meistens einzelne Teile des Systems, beheben selbst einfache Fehler oder geben bei
komplexeren Fehlersituationen den übergeordnete Instanzen Bescheid. Aus gemachten Fehlern
sollen diese Agenten für ähnliche, später auftretende Situationen lernen.
Der Aufwand zur Sicherstellung der Verfügbarkeit der Systeme wächst, wenn Kommunikationstechnologie
an Komplexität zunimmt.
- Arbeitsgruppen: Hier kommen wir zu den klassischen Multiagentensystemen, die ohne speziellen
Auftrag die Fähigkeit haben, ihre Aufgaben untereinander aufzuteilen. Selbständig können sie auf
Änderungen reagieren, indem sie andere Agenten informieren und Termine verschieben. Durchaus
möglich ist auch eine Rivalität, die dazu führt, dass sie auch konkurrierend arbeiten und nicht
kooperativ handeln, z.B. bei der Vergabe von beschränkten Ressourcen, wie etwa Hörsäle an gewissen
Universitäten :-).
- Electronic Commerce: Der automatische Manager für unsere Geldgeschäfte ist geboren! Intelligente
Agenten sind in der Lage, selbständig Geschäfte zu tätigen, z.B auch Preise zu vergleichen oder
beispielsweise für den Anwender die geeigneten, nach dem Persönlichkeitsprofil erforderlichen
Produkte, ausfindig zu machen.
- Informationsmanagement: Hier hinein fällt die aktive Suche im WWW mit der Unterstützung
von intelligenten Agenten. Agenten können, wie auch schon im Entstehungsdokument beschrieben,
sich den Bedürfnissen und Wünschen eines bestimmten Anwenders anpassen, indem sie seine
privaten Details erlernen, wie z.B. persönliche Gewohnheiten und Eigenschaften. Man kann sie mit
einem menschlichen Assistenten vergleichen, welcher die Aufgaben abnehmen kann, die man ihm
erteilt. Im Bereich des Informationsmanagements agieren auch passiv arbeitende Agenten, etwa
zur intelligenten Organisation eingehender Nachrichten.
In beiden Anwendungsfällen kann der Agent sowohl vom Anwender lernen, aber auch durch Einsatz
einer Art "social filtering", also durch Präferenzen von Benutzern mit potentiell
gleichen Interessen seine Fähigkeiten verbessern. Dies geschieht dann in Zusammenarbeit mit
anderen Agenten.
- Benutzerschnittstellen: Intelligente Agenten sind in der Lage, den Benutzer bei der Anwendung
komplexer Programme zu helfen oder gar selbst zur Benutzerschnittstelle werden. Somit sind die
Trojaner wieder in Mode und man erkennt hier auch deutlich die Gefahr des Virenbefalls, in Folge
den Ansatz der direkten Manipulation an Objekten hin zur Delegation von Aufgaben an Agenten
zum Erreichen eines Zieles. Diese indirekte Manipulation stellt einen
radikalen Umschwung in der Gestaltung der Mensch-Maschine Schnittstelle dar.
- Management von Geschäftsprozessen: Die Durchführung von Geschäftsprozessen wird schon
lange durch Informations- und Kommunikationstechnologie unterstützt. Anstatt diese von einer
zentralen Instanz überwachen zu lassen, kann dies von autonom agierenden Agenten
ausgeführt werden.
Nach [JEN] sind Agenten optimal geeignet, um bei verteilten Daten und Ressourcen, sowie zur
Steuerung eingesetzt zu werden. In den nun folgenden Kapiteln soll auf die mögliche
Unterstützung bei der Suche im wohl größten zusammenhängenden Datenbestand, dem WWW, durch
intelligente Agenten eingegangen werden.
Spezifische Entwicklungen und Auswirkungen
Mobile Agenten
Ursprünglich gab es in Netzwerken die beiden Konzepte der Applets und der
Servlets. Durch die Vereinigung der Funktionalitäten dieser beiden Konzepte
entstand dann das neue Konzept der mobilen Agenten.
Servlets laufen üblicherweise auf einem Server. Sie bieten irgendwelche Dienste an,
auf die dann andere Programme zugreifen können. Applets sind Programme auf den Endgeräten,
die auf Serverdienste zugreifen. Durch den Zugriff können sich die Applets Daten holen,
mit denen sie dann lokal (also auf den Endgeräten) weiterarbeiten. Wenn viele Daten für
eine Berechnung gebraucht werden, müssen dementsprechend viel Daten über das Netzwerk
übertragen werden. Das kann sowohl hohe zeitliche Kosten als auch hohe finanzielle Kosten
verursachen und das Konzept der Applets und Servlets ist deshalb nicht immer brauchbar.
Im Konzept der mobilen Agenten geht es nun darum, dass die beiden Funktionalitäten der
Applets und Servlets, zusammengeführt werden. Die Applets und die Servlets agieren am
selben Ort. Nun werden nicht mehr die Daten übertragen, die für eine Berechnung notwendig
sind, sondern es wird gleich das Programm, das zur Berechnung notwendig ist, - also der
mobile Agent - übertragen.
Die Vorteile, die sich aus der Architektur der mobilen Agenten ergeben, sind etwa eine
geringere Netzwerkbelastung (""Die Berechnungen sollen zu den Daten verschoben werden,
nicht die Daten zu den Berechnungen"").
Weiters können mit dem Konzept der mobilen Agenten auch Echtzeitapplikationen einfach
realisiert werden. So können Anforderunngen einfacher und schneller bearbeitet werden,
wenn die Programme, die die Berechnungen durchführen, zu den Programmen geführt werden,
auf die reagiert werden soll. Dazu ist klarerweise auf den Rechnern, auf denen die mobilen
Agenten eingesetzt werden sollen, eine Host-Engine notwendig. Durch diese Host-Engines
werden Orte zur Verfügung gestellt, auf denen die mobilen Agenten dann ausgeführt
werden können.
Ein weiteres strategisches Argument für den Einsatz von mobilen Agenten bzw. für das
vorteilhafte Konzept der mobilen Agenten ist die Anpassung an Umweltveränderungen.
Dieses Schlagwort bedeutet nichts anderes, als dass mobile Agenten auf diverse Situationen
in ihrer Umgebung reagieren können. Wird etwa ein Rechner, auf dem gerade ein mobiler Agent
läuft, heruntergefahren, so kann sich der mobile Agent autonom einen neuen passenden Host
(einen neuen passenden Ort) suchen, um dann mit den Berechnungen fortzufahren.
Auch bei Ressourcenknappheit kann ein mobiler Agent sich autonom einen neuen Host (einen
neuen Ort) suchen, der vielleicht mehr Ressourcen bietet und der mobile Agent seine
Berechnungen somit schneller, sicherer und ressourcen-schonender beenden kann.
Das Konzept der mobilen Agenten, dass sich die mobilen Agenten im Netz selbst fortbewegen
können und dann auf anderen Hosts, auf denen die Hosts-Engines laufen, weiterlaufen können,
hat auch Auswirkungen auf die Programmierung derselben.
Bei der Programmierung von mobilen Agenten können sich die ProgrammiererInnen auch teilweise
auf die Dienste der Host-Engines verlassen. So wird es möglich gewisse Dienste schneller
und einfacher zu implementieren. Als Beispiel sei hier genannt, dass schon einige
sicherheitsrelevante Bereiche von der Host-Engine zur Verfügung gestellt werden können.
Somit geht das Einbinden von neuen Diensten relativ mühe- und problemlos.
Ein essentieller Punkt, der bei der Entwicklung des Konzeptes der mobilen Agenten schnell
klar wurde, ist, dass die Host Engines möglichst plattformunabhängig sein müssen, damit die
mobilen Agenten dann auch auf möglichst vielen Hosts laufen können.
Es gibt mittlerweile schon Programmiersprachen, die sich auf Plattformunabhängigkeit
spezialisieren. Als Beispiel sei hier Java genannt. Gerade bei dieser
Programmiersprache gibt es allerdings in Fachkreisen Bedenken wegen sicherheitsrelevanten
Mängeln. Es ist nicht klar, ob Java den sicherheitskritischen Anforderungen der mobilen
Agenten gerecht wird. Nichtsdestotrotz wird Java heute häufig für die Implementation von
mobilen Agenten verwendet.
Auch die Standardisierung der Agent Frameworks ist dringen notwendig. Nur so kann
gewährleistet werden, dass Programme, die man einmal schreibt, überall laufen. Wenn es
Unterschiede in den Agent Frameworks gibt, dann ist dies nicht möglich und es entsteht bei
einem Wechsel des Agent Frameworks ein erheblicher Mehraufwand.
Die Umsetzung des Konzeptes der mobilen Agenten findet heutzutage eigentlich hauptsächlich
in Forschungsarbeiten an Universitäten statt. Es gibt mittlerweile auch Simulationssysteme,
die die Eigenschaften von mobilen Agenten simulieren und beobachten helfen.
Der wirtschaftliche Erfolg von mobilen Agenten steht noch aus, da - wie schon erwähnt - die
häufigste Umsetzung im Moment noch an Universitäten erfolgt, um mobile Agenten genauer zu
studieren. Es gibt jedoch auch schon Pläne bei Banken, die den Einsatz von mobilen Agenten
berücksichtigen.
Weiters ist die Umsetzung des Konzeptes der mobilen Agenten auch in Fertigungssystemen bzw.
in der Fertigungstechnik ganz allgemein zu beobachten.
Multiagentensysteme
Variationen von Informationsagenten im WWW
Die Entwicklung der ersten Informationsagenten begann, wie bereits erwähnt wurde, mit dem
weltweiten Erfolg des World Wide Web. Die Problemstellung war und ist, wie man den enormen
Informationsgehalt des WWW für den einzelnen Benutzer zweckmäßig aufbereiten kann. Jetzt galt
es eine adequate Lösung für dieses Problem zu finden.
Die ersten nennenswerten Umsetzungen begnügten sich damit, eine "stand-alone" Lösung zu sein.
Das soll heissen, die Informationsagenten waren in eine eigens dafür erzeugte Software
implementiert. Von grafischen Spielereien und user-freundlichkeit war damals noch nicht viel
zu erkennen. Es war einfach eine schlichte Software die die an sie gestellten Anforderungen
mehr oder weniger gut lösen konnte.
Eine grosse Akzeptanz war damit noch nicht möglich. Man beschloss also, die Informationsagenten
als "plug-ins" zu implementieren. Auch hier wiederum waren die ersten Entwicklungen auf
spezielle Browser zugeschnitten. Das bereits in Kapitel 3 genannte System, BASAR, war eines
dieser Systeme. BASAR arbeitete mit dem Webbrowser MOSAIC zusammen. Mittlerweile wurden die
Entwicklungsarbeiten an BASAR eingestellt.
Darauf folgten dann Lösungen wie Letizia, ein Informationsagent welcher mit Netscape
zusammenarbeitet. Letizia kann in Netscape integriert werden, und teilt den Bildschirm in
3 Teile. Somit wird zwar das ersprüngliche Browsingfenster verkleinert, aber man hat sozusagen
das Gefühl das Letizia ein Teil des Browsers ist. Für eine nähere Beschreibung von Letizia
siehe Kapitel 3 und [AGE].
Woran liegt es nun das solche Tools die den User eigentlich das Leben erleichtern sollen,
noch nicht wirklich eine grosse Verbreitung erfuhren? Einerseits liegt es wohl daran, dass
die meisten Systeme nicht über eine wirklich ansprechendes Layout verfügen. Man könnte das
Layout als zweckmäßig und minimal bezeichnen. In Kapitel 4, Rettungsversuche, wird erwähnt
mit welchen Überlegungen man versuchte dieses Problem in den Griff zu bekommen. Andererseits
dürfte ein Großteil der Computerbenutzer ein Misstrauen gegen solche Produkte hegen. Wobei
man hier wiederum eine Differenzierung in zwei Gruppen bilden könnte. Zum einen, fühlen sich,
vor allem ältere Menschen sozusagen "nicht sehr wohl", wenn sie merken, dass der PC soetwas
wie Intelligenz aufweist. Zum anderen existiert die Furcht, dass solche Agenten, die ja die
Informationen aus den Gewohnheiten des Users filtern, zu zwecken der Spionage benutzt werden.
Auf [KUE] existiert übrigens eine Sammlung von Links zu den verschiedensten Informationsagenten,
wo man sich einen ersten Eindruck über die verschiedensten Implementierungen machen kann.
Auswirkungen auf die Informatik
Auf wirtschaftlicher Ebene kann man daher bis jetzt noch nicht wirklich von einem Durchbruch
sprechen. Suchmaschinen sind nach wie vor, die bevorzugte Art um Wissen im globalen Netz zu
akquirieren. Auf informatischer Ebene dagegen, sind solche Entwicklungen, jetzt nicht nur
bezogen auf Informationsagenten, ein Maß dafür was alles in diesem Bereich der künstlichen
Intelligenz möglich ist und nehmen einen wichtigen Stellenwert in der KI Forschung ein.
Aufgrund dessen, kommt Wissenschaftlern in diesem Bereich laut [FAW] doppelte Verantwortung zu.
Zum einen als Staatsbürger und andererseits als Fachmann auf diesem Gebiet der spezielle
Kenntnisse aufweisen kann. Aufgrund seiner Ausbildung kann der Wissenschaftler gewisse Phänomene
im Zusammenhang mit der Nutzung von Rechnern besonders gut beurteilen und
"gerade deshalb die Auswirkungen und Konsequenzen von bestimmten Entscheidungen und Entwicklungen
in mancher Hinsicht besonders kompetent beurteilen [FAW]".
Da intelligente Agenten immer mehr in komplexe Aufgaben und Entscheidungen involviert sind,
wird der Verantwortung des Informatikers eine grosse Rolle zugespielt. Dies betrifft nicht
nur eine entsprechende Qualitätssicherung der Produkte und Entwicklungen auf diesen Gebiet,
sondern auch die Sicherstellung der geeigneten Quailifikation der Personen in Zusammenhang
mit der Nutzung dieser intelligenter Agenten.
Laut [FAW] kann davon ausgegangen werden, dass die meisten Wissenschaftler
"für Fragen der Folgenabschätzung der aus ihrer Disziplin hervorgehenden
Technologien sensibel sind".
Computerwissenschaftler Gerd Döben Henisch, der unter anderem Theologie studierte,
antwortete zum Beispiel auf die Frage ob er nicht manchmal Angst habe, dass sich seine
Geschöpfe selbständig machen könnten und ein Eigenleben entwickeln:
"Diese Vorstellung sei zum einen bedrohlich, biete aber auch die Chance für neue Antworten
auf menschliche Existenzfragen: Wir müssen uns klar werden: Wer sind wir? Was wollen wir?".
Siehe hierzu [INM1].
Kleiner Exkurs: Döben Henisch arbeitet an einem sogenannten Knowbot mit dem Namen Knowbot4.male.
Dieses Stück Software handelt völlig autonom und lebt auf einer simulierten Insel. Es verfügt
über einen Tast-,Riech-,Gehör -und Geschmackssinn. Für Interessierte sei auf die Webseite [INM2]
verwiesen.
Der Leiter des Instituts, auf dem Döben Henisch seinen Knowbot verwirklicht hofft, das es durch
den Knowbot zu einer öffentlichen Diskussion gibt, die sich mit den Möglichkeiten virtueller
Realitäten auseinandersetzt. Man sieht, manche Forscher setzen sich intensiv mit den möglichen
Konsequenzen ihrer Entwicklungen und auch mit der Aufklärung der Öffentlichkeit auseinander.
Um die Wichtigkeit der Verantwortung der Informatiker, die sich durch intelligente Agenten und
auch der KI ergab, zu unterstreichen möchte ich noch folgendes Zitat von Döben Henisch aufführen:
"Mittlerweile aber kenne ich kein Argument, das zwingend sagt, diese Systeme können nicht so
sein wie der Mensch." [INM1]
Ein weiteres Schlagwort welches sich im Zusammenhang mit der fortschreitenden Entwicklung
intelligenter Agenten ergab, ist die Ethik (laut [SCJ]). Der Informatiker muss sich ethnischen
Aspekten bei der Entwicklung seiner Schöpfungen bewusst sein. Hier wäre, wie bereist weiter oben
schon kurz erwähnt, die Verletzung der Vertraulichkeit hervorzuheben. Intelligente Agenten sollen
und dürfen nicht zum Ausspähen von Verzeichnissinhalten dienen, die nicht explizit für die
Allgemeinheit gedacht sind (siehe hierzu auch Agentensicherheit). Homepages im WWW sind zum
Beispiel für die Öffentlichkeit bestimmt, private Dateien auf der Festplatte eines
Internetbenutzers nicht. Ausserdem ist auf den Umgangston der Agenten zu achten. Hier wäre zum
Beispiel die Beileidigung von Personen durch den Agenten hervorzuheben. Dies trifft natürlich
nur auf solche Agenten zu, die mit dem User kommunizieren. Intelligente Agenten sind in der
Regel nur so gut, wie der oder die Entwickler des Agenten es beabsichtigen.
Manche dieser oben genannten Aspekte die Informatiker immer mehr berücksichtigen müssen, müssen
bereits in den grundlegenden Technologien eingearbeitet werden. Intelligente Agenten zeichnen
sich dadurch aus einen gewissen Grad an Autonomie aufzuweisen. Der Informatiker ist dafür
Verantwortlich wieviel Autonomie für einen Software Agenten, in Zusammenhang mit seiner Aufgabe
vertretbar ist. Die Replizierbarkeit von Agenten kann zum Beispiel sehr leicht für Viren
missbraucht werden. Andererseits müssen die Entwickler darauf achten, dass die Agenten nicht
zuviel Ressourcen, wie etwa Bandbreite oder Kapazitäten von Servern bei der Informationssammlung
für sich beanspruchen und somit den restlichen Betrieb festlegen.
Zusammenfassend kann man sagen, dass die Entwicklung von intelligenten Agenten weitreichende
Auswirkungen auf die Informatik mit sich gezogen hat. Aus diesen Gründen gibt es schon erste
Richtlinien für die Entwicklung, wie etwa die "Guidelines for Robot Writers" von [KOS] oder
den "Standard for Robot Exclusion".
Virtuelle Agenten
Interfaceagenten
Es werden für die unterschiedlichsten Bereiche, wie zum Beispiel Desktopanwendungen oder
Intra- beziehungsweise Internet, spezialisierte Agenten geben, die uns in manchen Bereichen
unsere Arbeit gänzlich abnehmen werden. Viele Benutzer werden sich über solche Erleichterungen
freuen und die immer wieder neuere Software auf ihren Rechnern installieren, um sich Arbeit zu
ersparen. Jedoch wird es auch Benutzer geben, die kritisch gegenüber stehen werden, und sich
vorsichtig mit dieser neuen Materie anfreunden oder überhaupt lieber die Arbeit selbst machen.
Ob sich überhaupt was wesentliches mit Agenten ändern wird ist fraglich, denn es gibt schon
heute viele Berufsklassen die mit einer Menge von Informationen herumwalten müssen, und sie
müssen herausfiltern können welche Nachrichten wirklich wichtig sind und welche nicht, und
das wird später auch nicht der Agent lösen können[cmr].
Pattie Maes (1994) fand aus einen Nutzertest heraus, dass von vielen der Wunsch geäußert worden
ist, eine Erweiterung durchzuführen, um den Agenten ausdrücklich mitzuteilen wenn die
Automatisierung bestimmter Handlungen nicht erwünscht ist. So haben sich auch viele gewünscht
das die Handlungen von Agenten widerrufbar sind und mit dokumentiert werden. Eine weiter
wesentlich Frage musste man sich noch beschäftigen und zwar wie weit man der Software vertrauen
kann wenn es um Daten geht unabhängig ob wichtig oder unwichtig. Nach Maes(1994) hängt das
soweit zusammen wieweit die Benutzer Einblick in die Lernentwicklung des Agenten haben. Beim
Agenten mit wissensbasierten Ansätzen ist oft das Vertrauen geringer als bei lernenden Agenten,
da sich die Benutzer nicht erklären können wo sich der Agent sein Wissen angelernt haben könnte.
Er kann die Entwicklung des Agents mit wissensbasierten Ansatz nicht mit beobachten und er
weiß nicht auf welcher Basis er die Handlungen durchführt.
Im Gegensatz dazu, kann er beim lernenden Agenten das Modell selbst kreieren, kann selbst
bestimmen was der Agent lernen soll und er kann ihn von Anfang an beobachten. Der Benutzer
hat das Gefühl das er den lernenden Agenten noch kontrollieren kann, jedoch beim wissensbasierten
Agenten ihm völlig ausgeliefert ist[cmr].
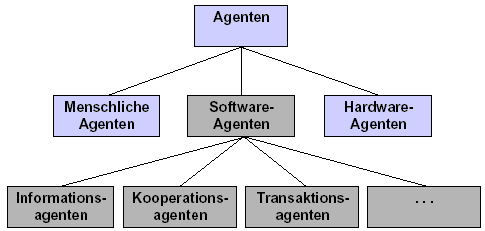
Vieles was Softwarefirmen als Agenten ausgeben, ist meist nur eine bessere Suchmaschine.
Bis heute gibt es noch keinen Agenten der die gewünschte und ideale Arbeit vorrichtet, es gibt
nur verschiedene Ansätze (siehe Abbildung Ansatz), wie Informationsagent (Informationen finden),
Kooperationsagent (Kommunikation zwischen verschieden Objekte) und Transaktionsagent
(Ausführung und Überwachen von Transaktionen).
Anwendungsbereiche wo Agenten eingesetzt werden ist zum Bespiel bei der Medizin[mez], dort
bieten sie einen zielsicheren effizienteren Zugriff auf vorselektierten Informationen. Sie
können den Arzt helfen eine schnellere und sichere Diagnose zu bekommen. Es ist für den Arzt
eine wesentlich Erleichterung, da man nach verschiedene Krankheitsbilder und deren Diagnosen
und Behandlungsmethoden suchen kann. Um dies so gut wie möglich zu realisieren, muss man
zuerst ein Wissensmedien für intelligente Agenten kreieren. Unter einem Wissensmedien versteht
man die Bewegungslandschaft in dem sich der Agent bewegen kann, es ist so ein Art Speicher
wo Wissen gespeichert werden kann. Auch ist wiederum die Kommunikation von großer Bedeutung.
Anwendungsgebiete für Interface-Agenten sind zum Beispiel[uf], Unterhaltung, Filterung von
Daten, Kaufen und Verkauf im Benutzerinteresse, führen und leiten durch unbekannte Umgebung
(wie etwa Programme) oder auch E-Commerce.
Bei E-Commerce [runt] können Agenten sowohl von Anbieter als auch von Nachfragern eingesetzt
werden. So werden heute schon Agenten von den Anbietern für Personalisierung und Werbung von
Produkten eingesetzt. Nachfrager benützen Agenten für Such- beziehungsweise Filterfunktionen,
um so die Sucherfolge des gewünschten Produkts zu erhöhen. Nachfrage-Agenten sind auch selbst
in der Lage, selbständig komplexe Preis und Vertragsverhandlungen durchzuführen. Jedoch
unterstützen Agenten nicht den Kauf und die Lieferung sowie den Service. Besonders in dieser
Sparte werden sich Agenten ausbreiten, da sie eine wesentliche Erleichterung für den Käufer
darstellen und den Verkäufern können sie helfen, ihre Kunden zielgenauer anzusprechen.
Was schon realisiert in diesem Bereich wurde[uf], wird in folgender Abbildung gezeigt
(Stand 2000).
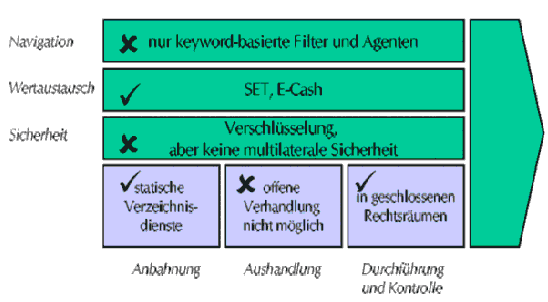
Beispiel für den elektrischen Einkauf wäre Büroeinkauf. Der Einkäufer eines Unternehmens
überträgt Teilaufgaben beim Einkauf von Büromaterial. Der Agent muss nun Anbieter im Internet
finden, und das Sortiment der Anbietern durchsuchen um das gewünschte Material zu finden.
Die verschiedenen Angebote liefert er den Einkäufer. Nun kann im der Einkäufer weitere Aufgaben
übertragen, wie etwa den Markt beobachten und Preisänderungen registrieren, Kaufzeitpunkte
vorschlagen, Lagerbestände verfolgen und so weiter[kogs].
Referenzen
[JEN] Nicholas R. Jennings, Michael J Wooldridge
"Agent Technology"
Springer Verlag, 1998
[GRE]
>[http://www.iicm.edu/greif]
[IC2]
>[
http://www.iicm.edu/thesis/hforstinger]
[FAW]
>[
http://www.faw.uni-ulm.de/deutsch/publikationen/radermacher/kuenstliche_intelligenz.html]
[INM1]
>[
http://www.inm.de/info/inm_info/d-echo_231196.html]
[INM2]
>[
http://www.inm.de/kip/kip.html]
[SCJ] ScJa1998
[KOS] Koster, M.: Guidelines for Robot Writers, 1993
>[
http://info.webcrawler.com/mak/projects/robots/guidelines.html]
[KUE]
>[
http://www.kuenstliche-intelligenz.de/Thema/Informationsagenten-Serviceteil.htm]
[AGE]
>[
http://agents.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia-AAAI/Letizia.html]
[cmr]
>[
www.cmr.fu-berlin.de/~mck/courses/lv00ss/ PeKMan/team7/agentenkapitel.pdf]
[mez] Effiziente Informationsbeschaffung im Gesundheitswesen, K.H. Schmidt
[uf] Universität Freiburg, Institut für Informatik und Gesellschaft, Prof. Dr. Günter Müller
[runt]
>[
www.runte.de/matthias/publications/ agents_clement_runte_dermarkt.pdf]
[kogs]
>[
http://kogs-www.informatik.uni-hamburg.de/old/COURSES/ material/p3_99/P3_Vorlesung13.pdf]
Weiterführende Informationen
Verweise auf Arbeiten anderer gruppen
>Entstehungskontext | Konzepte und Techniken | Entwicklung und Auswirkungen | Praxis | Bewertung