Wissen > 7. Knowledge Engineering > 7.4 Konzepte und Techniken
Ende der 70er Jahre merkten die Entwickler von Artificial Intelligence-Systemen, dass nicht alleine Formalismen und Inferenzschemen wichtig für das Lösen von Problemen sind. Einen weitaus wichtigeren Teil stellt das spezifische Wissen dar, das das System besitzt. [2]
To make a program intelligent, provide it with lots of high-quality, specific knowledge about some problem area.
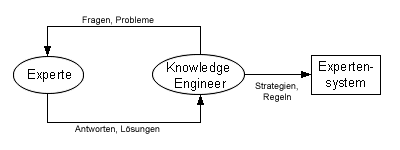
Diese Aussage legte den Grundstein für die Expertensysteme. Der Vorgang, ein Expertensystem zu erstellen wird Knowledge Engineering genannt. Ursprünglich stellte es eine spezielle Interaktion zwischen einem Experten in einem gewissen Fachgebiet und einem Knowledge Engineer dar. Der Knowledge Engineer extrahiert das Wissen des Experten, um daraus die Prozeduren, Strategien und Regeln zum Lösen eines Problems zu erstellen.
Das Ergebnis ist ein Computer-Programm, dass Probleme in der selben Weise löst, wie ein menschlicher Experte es machen würde.
Im Laufe der Zeit entwickelten sich weitere Konzepte der Wissensakquisition. Diese werden weiter unten noch vorgestellt.
Expertensysteme fallen in die Kategorie der wissensbasierten Systeme. Eine der Eigenschaften von wissensbasierten Systemen ist, dass eine Trennung zwischen der Wissensbasis und der Inferenzkomponente stattfindet. [2]
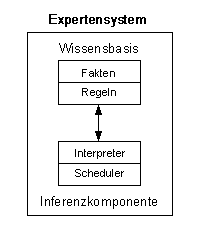
Die Wissensbasis stellt das Grundwissen des Systems dar, die Inferenzkomponente wendet das Wissen effizient an, um eine Lösung eines Problems zu erzielen.
Die Wissensbasis besteht grundsätzlich aus 2 verschiedenen Arten von Wissen:
Das Wissensbasis macht ein Expertensystem erst intelligent. Desto vollständiger ein spezieller Wissensbereich in einem Expertensystem abgebildet ist, desto besser ist das System. Dieses Wissen muss natürlich erst einmal in das System eingegeben werden, was als Wissensakquisition bezeichnet wird.
Man unterscheidet 3 verschiedene Grundmodelle der Wissensakquisition:
Die Inferenzkomponente besteht aus folgenden Teilen:
Es ist nicht immer eine eindeutige Trennung der beiden Komponenten möglich, da die Struktur der Inferenzkomponente stark von der Wissensbasis und der Repräsentation des Wissens abhängt.
Die Inferenzkomponente kann unterschiedliche Ausprägungen aufweisen. Z.B. ist im System EMYCIN die Inferenzkomponente ein Teil des Systems, wobei hingegen in der Programmiersprache LISP keine Inferenzkomponente vorhanden ist und der Designer selbst eine implementieren muss. Der Vorteil ist, dass die Inferenzkomponente komplett an die Wissensbasis angepasst werden kann. Dies geht aber leider auf die Kosten des Entwicklungsaufwands.
Um die Regeln auszuwerten, verwendet die Inferenzkomponente Heuristiken anstatt Algorithmen, wie es in konventionellen Programmen geschieht. Die Heuristiken liefern akzeptable Lösungen, Algorithmen zwar im allgemeinen optimale, jedoch auf Kosten von Rechenzeit. Ein weiterer Grund, warum Heuristiken verwendet werden, ist, dass es möglich sein kann, dass kein Algorithmus zur Lösung eines Problems besteht.
Um den Unterschied zwischen Heuristiken und Algorithmen zu verdeutlichen, ein kleines Beispiel:
Um die Entführung eines Flugzeuges zu verhindern, darf man keinen Entführer einsteigen lassen.
Es wäre unmöglich, den Algorithmus auf Flughäfen zu verwenden. Deshalb behilft man sich dieser Heuristik, was natürlich (wie die Vergangenheit gezeigt hat) zu Problemen führen kann.
Im Normalfall liefert eine Heuristik in einem Expertensystem ein "genug gutes" Ergebnis.
Verweise auf Arbeiten anderer Gruppen: