"We are drowning in information,
but starving for knowledge!"
(John Naisbett)
Einleitung
Data Mining und Data Warehousing beschäftigen sich mit der
Wissensextraktion aus Datenbanken.
Mit Hilfe von Algorithmen, deren Ursprünge vorrangig in den
Disziplinen der Statistik, Artificial Intelligence und Machine
Learning liegen, werden beim Data Mining aus großen
Datenbeständen vlautomatisch oder automationsunterstützt
neue Inhalte "gewonnen", Muster und Trends erkannt, sowie Prognosen
für die Zukunft erstellt.
Im Gegensatz zum auf die Methoden zur Mustererkennung und
Regelextraktion spezialisierten Data Mining zielt der Begriff des
Data Warehousing mehr auf die (auch: betriebliche)
Infrastruktur zum Datenmanagement ab. Ein Data Warehouse im engeren
Sinne ist ein zentraler Datenbehälter ("Repository" [6] ), der Daten aus unterschiedlichen, meist
heterogenen Quellen und mehrere Sichten auf den
Original-Datenbestand enthält. "Data Warehousing" ist im
übrigen ein eher im (betriebs-)wirtschaftlichen Kontext
gebräuchlicher Begriff, namentlich auch im näheren Umfeld
von decision support (siehe auch Abschnitt
"Zitate zum Begriff Data Warehousing"; [5]
)
Wissenschaftliches Umfeld, historische Entwicklung
Die ältesten Wurzeln des Data Mining liegnin der klassischen
Statistik , erste richtungsweisende Aktivitäten findet
man in den 60er und 70er Jahren. Wesentlich für die Abgrenzung
des "modernen" Data Mining von der ursprünglichen Statistik
ist die Tatsache, dass im Gegensatz zum klassischen Hypothesentest,
bei dem man eine Annahme mit den Daten konfrontiert und
anschließend aufgrund exakt definierter mathematischer
Überlegungen annimmt oder verwirft, nunmehr versucht, die
Hypothesen quasi erst im Nachhinein zB in Form von Regeln aus den
analysierten Daten abzuleiten.
Die Artificial Intelligence (AI) versucht, basierend auf
Heuristiken, dem menschlichen Denken ähnliche Prozesse auf
statistische Probleme anzuwenden. Da dieser Ansatz aber hohe
Ansprüche an die Rechenleistung der eingesetzten
Computersysteme stellt, ist er bis in die 80er Jahre nicht
praktikabel.
Das Machine Learning kommt erst in den 80er und 90er Jahren
auf und profitiert im Gegensatz zur wirtschaftlich wnier
erfolgreichen AI früherer Prägung vom stetig steigenden
Preis-/Leistungsverhältnis der zu diesem Zeitpunkt
erhältlichen Rechenanlagen. Die Disziplin, die kurz als
Zusammenfassung von Statistik und AI beschrieben werden kann,
versieht AI-Heuristiken mit fortschrittlichen statistischen
Analysemethoden und versucht, Computerprogramme anhand der von
ihnen studierten Daten lernen zu lassen. [7]
Data Mining: Wissenschaftliches Umfeld
Motivation, Entstehungskontext, Spannungsfelder
Praktisch alle größeren Unternehmen und anderen
Organistationen sammeln (im Zuge des verstärkten
Computereinsatzes, automatisch oder automationsunterstützt;
Tools für das automatisierte Anhäufen von Daten sind
mannigfaltig verfügbar) groß Daenmengen mit einem oft
hohen Maß an Heterogenität an; unterschiedliche
Datenbestände in den einzelnen Abteilungen und
Unterorganisationen reflektieren deren jeweilige
Teilaktivität. Das in diesen Daten enhaltene bzw verborgene
Wissen ist nicht offensichtlich: Niemand hat den Überblick
über alle Datenbestände, und die personellen
Zuständigkeiten wechseln - Daten werden dadurch falsch
interpretiert oder "uninterpretierbar". Anders ausgedrückt:
"We are drowning in information, but starving for knwledge" (John
Naisbett; freie Übersetzung: "Wir ertrinken in Informationen,
aber uns dürstet nach Wissen!").
[6]
Vor dem Hintergrund dieser "Missstände", dem allgemeinen
Wettbewerbsdruck, der immer billigeren und leistungsfähigeren
Computer und der weit entwickelten theoretischen und mathematischen
Grundlagen (Machine Learning, Statistik, Datenbansystme) erscheint
die EDV-gestützte Datenanlyse mit Data-Mining-Algorithmen
heutzutage als das Mittel der Wahl zum verbesserten
Datenmanagement.
[6]
Auch die Bezeichnung "Data Mining" spiegelt im übrigen recht
treffend das Bedürfnis wieder, die in der Datenmine
verschütteten bzw. begrabenen (man spricht auch vom
"Datenfriedhof"), unter der Oberfläche jedoch vorhandenen
Informationen aus den Untiefen übergroßer Datenbanken
ans Tageslicht zu befördern.
Begriffsdefinitionen
Wie scheinbar alle Begriffe im Bereich Wissensakquisition und
Knowledge Management, sind auch "Data Mining" und "Data
Warehousing" zwei mit zahlreichen Mehrdeutigkeiten und inhaltlichen
Überschneidungen (auch mit anderen Wissensgebieten) behaftete
Begriffe. Die Ausdrücke wurden erst in der jüngeren Zeit
geprägt (ca. ab 1990, Publikationen zum Thema häufensich
rst in der zweiten Hälfte der Neunziger Jahre).
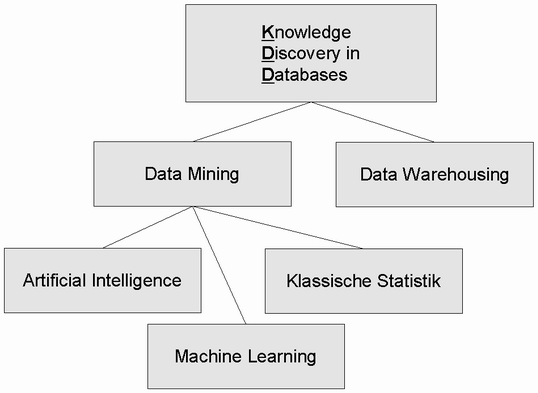
Knowledge Discovery in Databases
Als etwas abstrakteren Überbegriff, der unter anderem Data
Mining und Data Warehousing umfasst, findet man Knowledge
Discovery in Databases (KDD) . Der KDD-Prozess umfasst
zusätzlich zu Data Mining und Data Warehousing die Schritte
Datenpräparation, Datenauswahl, Datensäuberung, Aufnahme
von geeignetem Vorwissen sowie die Ergebnisinterpretation des Data
Minings. [5]
Zitate zum Begriff "Data Mining"
"the nontrivial extraction of implicit, previously unknown and
potentially useful information from data" [1]
"the automated extraction of hidden predictive information from
databases" / "extension of statistics, with a few artificial
intelligence and machine learning twists thrown in" - purpose:
"analyze large databases to solve business decision problems" [2]
informtion-extraction activity": the goal is to "discover
hidden facts contained in DB's" - techniques: "machine learning,
statistical analysis, modeling techniques, database technology" -
purpose: "finds patterns and subtile relationships in data and
infers rules that allow prediction of future results" - typical
applications: "market segmentation, customer profiling, fraud
detection, evaluation of retail promotion, credit risk analysis" [3]
Zitate zum Begriff "Data
Warehousing"
"current business trends in collecting and cleaning
transactional data, and making them available for analysis and
decision support" [5]
Data-Mining-Techniken
Jede Technik ist meistens für ein spezifisches Problem
besonders geeignet. Es gibt eine Unmenge an Techniken von denen die
wichtigsten hier aufgezählt sind.
Warenkorbanalyse
Gehört zu den Clusteranalsen. Be der Warenkorbanalyse werden
Gruppen von häufig gemeinsam verkauften Produkten aufgefunden.
Damit kann das Kaufverhalten analysiert werden. Die daraus
resultierenden Ergebnisse werden verwendet, um
Produkte in einem Regal nebeneinander oder weiter auseinander
platzieren zu können.
Kaufwahrscheinlichkeiten für Produkte errechnen zu
können.
Personenbezogene Werbeaktionen starten zu
können
Fallbasiertes Schließen
Verfahren, bei dem Entscheidungen aus den Erfahrungen der
Vergangenheit abgeleitet werden. Dazu werden alle Eigenschaften von
einzelnen Fällen in einer Datenbank gespeichert, zum Beispiel
alle relevanten Parameter zur Entscheidungsfindung sowie der
Ausgang des Geschäftsfalls. Um ähnliche Fälle zu
finden werden vorhandene Parameter mit den Parametern der Datenbank
verglichen. Wichtig ist dabei, die Parameter aller relevanten
Unternehmensentscheidungen zu protokollieren, um immer genuere undbessere Vorhersagen treffen zu können.
Neuronale Netze
Bestehen aus vielen einfachen Einheiten, den Neuronen. Diese
tauschen Informationen per Stimulationen über gerichtete
Verbindungen aus. Um so ein Netz sinnvoll verwenden zu können,
muss es anhand von Beispielen trainiert werden. Dabei unterscheidet
man zwei Arten des Lernens:
Überwachtes Lernen wird verwendet, um
Datenklassifizierung und Vorhersage zu realisieren. Zum Beispiel
kann man es verwenden, um den Trend von Umsatzentwicklungen eines
Unternehmens zu beliebigen Zeitpunkten zu berechnen. Trainiert wird
hier mit Beispielen aus der Vergangenheit.
Unüberwachtes Lernen wird zur
Datensegmentierung verwendet. Einsatzgebiet ist zum Beispiel die
Zielgruppenanalyse. Hierbei sucht das neuronale Netz nach Mustern
in den Kundendaten, um anhand dieser Muster die Kunden bestimmten
Zielgruppen zuzuordnen.
Genetische Algorithmen
Das Prinzip esteht dain, die Natur nachzubilden. Jede Lebensform
entwickelt sich von Generation zu Generation weiter und wird
dadurch „lebensfähiger“. Genetische Algorithmen
machen nichts anderes.
Der Grundbaustein ist ein „Chromosom“, das durch ein
Bitmuster dargestellt wird. Eine Menge von Chromosomen bildet eine
Population. Zwei Chromosomen werden ausgewählt und gekreuzt,
wodurch sich die Population ändert. Anschließend wird
jedes einzelne Chromosom einer Fitnessfunktion unterzogen. Es
bleiben nur noch die stärksten Chromosomen übrig, die
sich dem Problem optimal angenähert haben.
Diese Methode wird bei Optimierungsaufgaben häufig
eingesetzt.
Automatische Clusteranalyse
Dient dazu, Gruppen von Datensätzen zu finden, die
Ähnlichkeiten aufweisen. Ausgegangen wird von den vorliegenden
Rohdaten, in denen Zusammenhänge gesucht werden. So werden
Daten mit ähnlichen Eigenschaften gesichtet. Diese
Datnbestände werden mit anderen Techniken weiteruntersucht.
Beispiel: Kunden einer Bank werden nach ihrem Kreditrisiko
eingestuft
Analyse von Beziehungen zwischen den Datensätzen
Es werden Beziehungen zwischen den Datensätzen hergestellt, um
zum Beispiel Marketingaktionen auf einzelne Kunden besser abstimmen
zu können.
Data Mining in der Praxis
Allgemeines
Data Mining entwickelt sich im wesentlichen in zwei Gebieten:
Einerseits in der Forschung, hier liegt das Hauptziel darin, neue
und effizientere Algorithmen zur Informationsgewinnung aus
beliebigen Daten zu finden, und andererseits in der Praxis, in der
Data Mining hauptsächlich dazu eingesetzt wird, um
Wettbewerbsvorteile gegenüber der Konkurrenz zu erreichen.
In folgenden Branchen können unter anderen
Datenanalysemethoden wie Data Mining für Marketingzwecke
genutzt werden:
Banken
Bausparkassen
Versicherungen
Handel
Telekommunikationsunternehmen
Vor allem in diesen Branchen verfügen die einzelnen
Unternehmen über große Datenmengen über ihre
Kunden. Aufgabenstellungen sind dabei zum Beispiel das Erkennen von
Kundengruppen, Kreditwürdigkeitsanalyse, Warenkorbanalyse usw.
Dabei kommen die verschiedensten Techniken
zum Einsatz.
Probleme
Die Probleme des Data Mining in der praktischen Anwendung liegen
weniger an der mangelnden Güte der einzelnen Techniken als in
der Datengrundlage, den verwendeten Tools und der Einbettung in die
Geschäftsprozesse. Diese drei Problemfelder seien hier kurz
näher beschrieben:
Datengrundlage: Hier besteht die Schwierigkeit darin,
dass die Daten für die operativen Abläufe in
verschiedenen Geschäftsbereichen mit mehr oder weniger
verschiedenen Datenmodellen gesammelt werden, was eine
ungünstige Analysesituation entstehen lässt.
Zielführend wäe es hier, wenn man mit dem Data Mining auf
einem speziell für die Analyse aufgebauten Data Warehouse
aufsetzen kann.
Tools: Heutige Data Mining-Tools setzen in der Regel auf
Tabellen auf, in denen das Untersuchungsziel (also zum Beispiel der
Kunde) Schlüssel ist. Sie unterstützen weder bei der
Verwaltung von Analysen, noch sind sie für die jeweilige
Aufgabenstellung optimiert. Folgende Aufgaben bleiben bei der
Verwendung solcher Tools dem Benutzer zu tun:
das zweckbezogene Sammeln relevanter Daten
die Identifikation der Problemart
das Ermitteln der Parameter eines Verfahrens
Vor allem von der Weiterentwicklung der Tools wird es
abhängen, ob sich Data Mining auch in der Zukunft behaupten
kann.
Einbettung: Ein wesentlicher Punkt des Data Mining in
der Praxis besteht auch in der Umsetzung der gewonnen Erkenntnisse.
Eine wichtige Rolle dabei spielt die zeitliche Komponente on
Informatinen. Verfahren setzen zu einem Zeitpunkt auf Daten auf,
Wissen wird gewonnen. Wann soll die nächste Analyse gemacht
werden? Wird bereits bekanntes Wissen genutzt und nur noch auf
Veränderungen aufmerksam gemacht? Welche Veränderungen in
den Kundengruppen gibt es? Wann ist eine aus dem Data Mining
gewonnene Regel zu korrigieren oder zu streichen? Auch von der
Beantwortung dieser Fragen wird es abhängen, ob das Data
Mining in der betrieblichen Praxis einen hohen Stellenwert
erreichen kann.
Datentrends: Das explosive Wachstum der Datenmengen
nimmt kein absehbares Ende, gleichzeitig bleibt die Zahl der
Absolventen mit naturwissenschaftlich-technischer Ausbildung
annähernd konstant. Der Großteil der aufgezeichneten
Daten bleibt also entweder auf den Datenträgern, ohne jemalswieder untesucht zu werden, oder neue Techniken und Verfahren - wie
Data Mining - sind in der Lage, den Vorgang der Extraktion,
Filterung und Analyse der Daten wenigstens zum Teil zu
automatisieren, um daraus Wissen für Entscheidungen zu
gewnnen.
Hardwaretrends: Die preisliche und technische
Entwicklung der gängigen Hardware ermöglicht es,
Datensätze zu untersuchen, die von ihrem Umfang her noch vor
wenigen Jahren nicht hätten untersucht werden können.
Dieser Trend wird sich allem Anschein nach in den kommenden Jahren
fortsetzen.
Netzwerktechnik: Wie bei der übrigen Hardware
sinken die Kosten der Endgeräte und der in ständig
höherem Maße verfügbaren Bandbreite beständig.
Damit wird es möglich, auch auf mehrere Rechner verteilte
Datensätze mit der vorhandenen Technik zu untersuchen.
Wissenschaft: Neben Theorie und Experiment ist die
Simulation heute Standein nahezujeder technischen Entwicklung.
Hier spielt Data Mining eine wichtige Rolle als Verbindungsglied,
besonders wenn Experiment oder Simulation sehr große
Ergebnisdatensätze liefern.
Business: Alle geschäftsabläufe müssen in
Anbetracht des Wettbewerbsdrucks profitabler, reaktionsschneller
und gleichzeitig komfortabler für den Anwender sein als je
zuvor, wobei aber weniger Mitarbeiter zu geringeren Kosten
eingesetzt werden sollen. Data Mining ermöglicht es in diesem
Zusammenhang, Chancen und Risiken von Transaktionen mit Kunden und
Lieferanten automationsunterstützt genauer als bisher
einzuschätzen.
"Hype" oder echte Neuheit?
Data Mining erscheint nicht als echte Neuheit, sondern vielmehr als
logische Konsequenz der Entwicklungen der letzten Jahrzehnte im
Hardwarebereich. Es stellt hauptsächlich eine Neukombination
von Techniken aus Mathematik und Informatik dar, die schon seit den
Sechzigern Bestand haben
h3>Schlussfolgerungen Derzeit gibt es keine Anhaltspunkte
dafür, dass der Trend zum Data Mining nicht anhalten sollte.
Gerade mit der ungebrochenen Expansion des World Wide Web ergeben
sich (unter anderem im Bereich des Text Mining bzw. Web Mining)
immer neue Anwendungsmöglichkeiten - die Warenkorbanalyse ist
und bleibt beispielsweise von Interesse für jeden, der einen
Online-Shop auf die Beine stellen möchte. Auch die Anzahl der
wissenschaftlichen Publikationen zum Thema nimmt seit ca. 1990
zu.
Frawley, Piatetsky-Shapiro: "Knowledge Discovery in Databases:
An Overview"
"IEEE TRANSACTIONS ON NEURAL NETWORKS", VOL. 13, NO. 1, JANUARY
2002;
im Volltext als PDF unter http://www.ieee.org/ - kostenfrei
abrufbar im TUNET, zB über die Homepage der TU-Bibliothek (http://www.ub.tuwien.ac.at/
) unter "Elektronische Zeitschriften"
Vorlesung "Data Warehousing und Mining" - Klemens
Böhm