Wissen > 3. nicht klassische
Datenbanken > Verteilte Datenbanken
3.2 Verteilte Datenbanken
Übersicht
Entstehungskontext
Ursprüngliche Problemstellung
Die ersten Computersysteme waren sehr teuer und damit war klar, dass nur wenige
Systeme an ausgesuchten Standorten eingesetzt wurden. Nach und nach sanken die
Preise für Computersysteme und die EDV wurde in immer mehr Bereichen der
Unternehmen eingesetzt. Doch mit der immer stärkeren Verbreitung von Großkonzernen
musste die Rechnerleistung der einzelnen Standorte unter einem Hut gebracht
werden ([2]). Ein anderes Problem war das zur Verfügungstellen
der Rechnerleistung eines Großrechners an mehreren Standorten ([1]).
Beide Probleme haben eines gemeinsam: Die Daten werden an verschiedenen Orten
benötigt und haben einen Zusammenhang zu den Daten an anderen Orten.
Technische Voraussetzungen
- Es existieren verschiedenste Medien für die Vernetzung von Rechnern
und diese Verbindungen werden immer leistungsfähiger ([3])
- Kleinrechnersysteme werden möglich ([1], [2])
- Kosten für Massenmedien sinken doppelt so schnell wie für Datenverbindungen
([2])
Wirtschaftliche Voraussetzungen
- Es entstehen immer mehr Großkonzerne mit vielen Niederlassungen, die
eine gemeinsame Infrastruktur und Koordinierung wollen - Stichwort: Globalisierung
(Beispiel Bank of America in [2])
- Nach der Entwicklung eines vernetzten und ausfallssicheren Netzes (ARPANET)
sorgt sich das Militär nun auch um seine Daten. Das Militär erkennt
den Vorteil der Ausfallssicherheit und der Redundanz und fördert deshalb
verschiedenste Forschungen (Beispiel Department of Defense in [3])
Vorgeschichte
Die einzelnen Unternehmen wollten an allen Unternehmensstandorten die relevanten,
elektronisch gespeicherten Daten zur Verfügung haben. Aus diesem Grund
entwickelten die Programmierer der einzelnen Unternehmen proprietäre Lösungen
für die Verteilung von Daten.
Bei Unternehmen mit Großrechenanlagen mussten oft Geschäftsabläufe
mit Hilfe von telefonischen Rückfragen erledigt werden. Ein Beispiel ist
die Überweisung von größeren Geldbeträgen in einer entfernten
Filiale bei der Bank Of America [2].
Auch Finanzämter hatten mit der Verfügbarkeit von Daten zu kämpfen.
Nur im eigenen Finanzamt hatte man die Daten vorrätig. Die notwendigen
Daten der übrigen Finanzämter mussten dabei aufwendig mittels Magnetband
von den zentralen Großrechnern zu den einzelnen Ämtern gebracht werden
([1]).
Weitere Beispiele und deren Lösungsansätze sind in [2]
zu finden.
Die Gruppe 6 Wissensakquisition bringt mit den "spiderwebs" ([19])
auch ein gutes Beispiel für den Einsatz von verteilten Datenbanken.
Weltbild der Entwickler
Die Entwickler der ersten verteilten Datenbanken sind nicht wie heute üblich
in großen Softwarehäusern zu suchen, sondern waren in den EDV-Abteilungen
der einzelnen Unternehmen zu suchen. Die erstellte Software war aus diesem Grund
auch extrem spezialisiert auf die Anforderungen der Unternehmen.
Eine mögliche Angst, dass durch die Verteilung der Daten auch eine Abwanderung
der Kompetenzen aus bestehenden Großrechenzentren zu den einzelnen Standorten
entsteht, konnte nicht entdeckt werden. Vielmehr machte sich eine Euphorie unter
den Entwicklern breit, die Daten immer und überall zur Verfügung zu
haben.
Umfeld und Einflüsse
Die Entwickler der ersten verteilten Datenbanken waren in ihre Unternehmen
eingebettet und entwickelten eine spezielle Lösung für das Problem
in ihrem Unternehmen ([1], [2]). Dies lag
unter anderem daran, dass noch keine fertigen Datenbankprodukte von der Stange
existierten. Die Entwicklung von kommerziellen Datenbankprodukten lag damals
noch in den Kinderschuhen und hatte mit anderen Problemen zu kämpfen. Die
erste Implementierung der Datenbank INGRES gab es zwar bereits 1975 (mit all
ihren noch vorhandenen Kinderkrankheiten), doch an eine verteilte Datenbank
hatte damals noch keiner gedacht wie Stonebraker [4] zeigt.
Die Forschung nutzte anfangs die Erfahrung der vielen verschiedenen praktischen
Lösungen um eine umfassende Theorie darauf aufbauen und verfeinern zu können.
Die einzelnen Unternehmen hatten verschiedenste Ausgangsbedingungen und Ansätze
um eine optimale, verteilte Datenbank für ihr Unternehmen aufzubauen ([2],
[3])
Die Erwartungen der Forscher, was verteilte Datenbanken bringen werden, waren
damals (1977) sehr unterschiedlich. Die einen meinten, durch den Einsatz von
verteilten Datenbanken werden keine Großrechnersysteme mehr benötigt.
Die anderen wiederum dachten an eine Vernetzung von Großrechnersystemen.
In einem waren sich jedoch alle einige einig, verteilte Datenbanken besitzen
eine Zukunft ([2]).
Konzepte und Techniken
 Um
darzustellen welche Probleme in verteilte Datenbanken auftreten und durch entsprechende
Techniken gelöst werden müssen, ist es sinnvoll, ein paar Regeln für
verteilte Datenbanken zu betrachten. Chris Date stellte dazu 1987 in Analogie
zu den Coddschen Regeln ([16]) über relationale Datenbanksysteme
12 Regeln für verteilte Datenbanksysteme auf (folgende Regeln sind aus
dem Buch „Verteilte Datenbanken" ([6]) entnommen):
Um
darzustellen welche Probleme in verteilte Datenbanken auftreten und durch entsprechende
Techniken gelöst werden müssen, ist es sinnvoll, ein paar Regeln für
verteilte Datenbanken zu betrachten. Chris Date stellte dazu 1987 in Analogie
zu den Coddschen Regeln ([16]) über relationale Datenbanksysteme
12 Regeln für verteilte Datenbanksysteme auf (folgende Regeln sind aus
dem Buch „Verteilte Datenbanken" ([6]) entnommen):
- Benutzer eines verteilten DB-Systems sollten sich so verhalten können,
als ob das System nicht verteilt wäre. Alle Probleme, die ein verteiltes
DB-System mit sich bringt, sind auf der internen Implementierungsebene und
nicht auf der externen Benutzerebene zu lösen.
- Jeder Knoten eines verteilten DB-Systems muß zugleich ein für
sich autonomes System sein.
- Ein Knoten eines verteilten DB-Systems darf nicht von einem zentralen Knoten
abhängig sein.
- Jeder Knoten eines verteilten DB-Systems muß ununterbrochenen Betrieb
gewährleisten.
- Die Verteilung der Datenbanken im Netz ist für den Anwender nicht sichtbar.
- Fragmente einer verteilten Datenbank können an beliebigen Orten gespeichert
werden.
- Ein verteiltes DB-System muß die Speicherung von Replikaten an unterschiedlichen
Orten unterstützen.
- Datenbankanforderungen im Gesamtsystem müssen optimiert werden.
- Die Konsistenz rechnerübergreifender Transaktionen ist zu gewährleisten.
- Die Unabhängigkeit von der Hardware muß gegeben sein.
- Die Unabhängigkeit vom Betriebssystem muß gegeben sein.
- Die Unabhängigkeit vom Netzwerk muß gegeben sein.
- Ein verteiltes DB-System darf nicht von den eingesetzten Datenbankkomponenten
abhängig sein.
Man muss dabei allerdings festhalten, dass es kein verteiltes Datenbanksystem
gibt, dass alle diese Regeln erfüllt. Vielmehr sieht Chris Date den Sinn
der Regeln darin, auf die Probleme der verteilten Datenbanken aufmerksam zu
machen und je nach Anwendungsfall eine bestimmte Menge von Regeln zu beachten.
Alle Regeln könnten gar nicht erfüllt werden, da sich manche sogar
widersprechen (z.B. Regel 1 Autonomie und Regel 8 Konsistenz verteilter Transaktionen
über Rechnergrenzen).
Verteilung
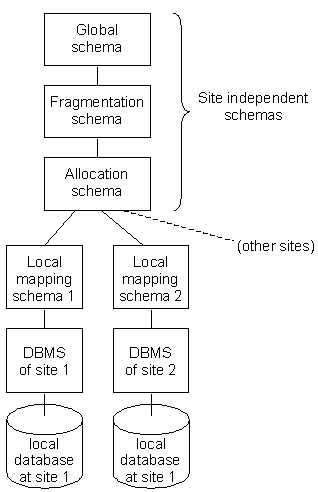
Die Referenzarchitektur hier zeigt, welche Schritte für eine Verteilung
der Daten notwendig sind. Eine verteilte Datenbank muss nicht alle Ebenen der
Referenzarchitektur erfüllen, aber die Architektur stellt einen guten Überblick
über die einzelnen Schichten in einer verteilten Datenbank dar.
Referenzarchitektur einer verteilten Datenbank (entnommen aus
[5])
- Global schema: Ist wie das relationale Schema. Quasi so als wäre überhaupt
keine Verteilung vorhanden.
- Fragmentation schema: Aufteilung der Daten des globalen Schemas. Dabei wird
zwischen horizontaler und vertikaler Fragmentierung unterschieden. Horizontale
Fragmentierung bedeutet z.B. eine Aufspaltung der Tupel einer Relation nach
Adresse, eine für Europa, eine für Amerika. Vertikale Fragmentierung
bedeutet eine Aufteilung der Tupel nach Attributen. Erstes Framgent Adresse,
zweites Rest. Eine Vermischung der beiden ist auch möglich.
- Allocation Schema: Dieses Schema bestimmt die Verteilung der einzelnen Fragmente
auf verschiedene Sites nach einem n:m Schema. D.h. jedes Fragment kann auf
mehrere Sites kommen (Redundanz) und jede Site kann mehrere Fragmente aufnehmen.
- Local mapping schema: Dieses Schema bestimmt, wie die Daten auf die lokalen
Datenbanken abgebildet werden. Bei heterogenen Datenbanksystemen wird dieses
Schema auf jeder Site anders sein.
Transaktionen
Verteilte Datenbanken nutzen ähnliche Techniken wie klassische Datenbanken
für das Transaktionsmanagement. Die Verwendung dieser Techniken ist bei
verteilten Datenbanken viel wichtiger als bei klassischen, da die Möglichkeit
von Einzelfehlern im System um ein Vielfaches höher liegt. Wichtig dabei
ist vor allem, dass die 3 Grundbedingungen für Transaktionsmanagement eingehalten
werden:
- Atomizität
- Dauerhaftigkeit
- Serialisierbarkeit
Die Techniken für das Erreichen dieser 3 Bedingungen seien hier nur kurz
erwähnt.
Sperrverfahren können als zentrale Lockmanager (Sicherheitsrisiko
Ausfall) oder als verteilte Sperrverfahren (Aufwendige Implementierung)
realisiert werden. Als Sperrprotokolle kommen unter anderem das Zwei-Phasen-Commit-Protokoll
und das Drei-Phasen-Commit-Protokoll zum Einsatz ([6]).
Deadlockerkennung bzw. -vermeidung ist ebenfalls sehr wichtig in verteilten Datenbanken.
Zu den verwendeten Techniken zählen:
- Timeout-Verfahren
- zentrale Deadlockerkennung
- hierarchische Deadlockerkennung
- verteilte Deadlockerkennung
- Zeitstempelverfahren
- Aktive und passive Deadlockvermeidung
Optimierung
Mit der Verteilung der Daten hat sich der Stellenwert der Abfragenoptimierung
enorm erhöht. Bedingt durch den relativ hohen Zeitaufwand für die
Datenkommunikation (im Vergleich zur lokalen Abarbeitung) ist es wichtig geworden,
eine effiziente und globale Abfragenoptimierung durchzuführen. Die Optimierung
soll dabei nicht nur stur SQL-Abfragen wie bei lokalen Datenbanken optimieren,
sondern auch gezielt Einfluß auf die Verteilung der Daten nehmen. Häufig
benötigte Daten (Tabellen, Attribute) werden lokal gehalten, während
der Rest auch woanders liegen kann. Dabei nutzt der Optimierer oft auch Techniken
des Datamining um Informationen über die vorhandenen Daten zu sammeln und
basierend auf diesen Informationen gezielt die Abfragen syntaxmäßig
zu optimieren ([6]).
Entwicklungen und Auswirkungen
Es gab viele Entwicklungsprojekte, die sich mit verteilten Datenbanken befassten.
Zu erwähnen ist hier sicher das Project R*, dass aus dem System
R hervorgegangen ist. Weitere Infos zum Project R gibt es bei [18].
Aber auch MULTIBASE, DDM, SDD-1, HiPAC, SIRIUS-DELTA, POREL, Daplex und ENCOMPASS
sind verteilte Datenbanken die in der Forschung entwickelt wurden ([12],
[6]). Kommerziell durchgesetzt haben sich davon nur wenige.
Aber die Ideen und Erkenntnisse dieser verteilten Datenbanksysteme fanden Einzug
in die Produkte der großen Hersteller.
Derzeitige und künftige Entwicklungen befassen sich mehr mit der Nutzung
von Clustern, um riesige Datenmengen mit möglichst geringen Antwortzeiten
zu nutzen. Parallel Databases und Loadbalancing heißen die neuen Schlagwörter
für verteilte Datenbanken ([13]).
Die reale Praxis
Verteilte Datenbanksysteme sind aus den Unternehmen nicht mehr wegzudenken.
Sie existieren in den verschiedensten Varianten und erfreuen sich großer
Beliebtheit. Proprietäre Implementierungen in Unternehmen sind heute im
wesentlichen nicht mehr vorhanden. Es existiert eine breite Palette von Produkten
wie Ingres ([10]), Oracle ([8]), Informix
([9]) oder Sesam/SQL ([11]) um nur einige
zu nennen. Allen gemeinsam ist, dass sie auf dem relationalen Schema aufbauen
und seit mindestens 15 Jahren im Einsatz sind. Heute kann kein großes
Datenbanksystem mehr existieren ohne umfassende Mechanismen für eine verteilte
Datenbank zu beinhalten.
Durchgesetzt haben sich im Laufe der Jahre verteilte Datenbanken, die auf dem
relationalen Modell und SQL beruhen ([14]).
Neben der typischen Nutzung von verteilten Datenbanken in geographisch verteilten
Standorten gewinnt heute die Nutzung als Cluster zunehmend an Bedeutung. In
einem Cluster werden mehrere Computer über ein schnelles LAN miteinander
verbunden und bilden zusammen eine große verteilte Datenbank auf die mit
kurzen Antwortzeiten zugegriffen werden kann - eine parallel database.
Die verwendete Technik für verteilte Datenbanken ist im wesentlichen die
selbe geblieben, nur die zugrundeliegende Hardware ist um ein Vielfaches billiger
und schneller geworden.
Eine Sonderform einer verteilten Datenbank existiert bereits seit 1981, das
von Dr. David Mills erfundene Domain Name System DNS ([7]).
Das DNS ist heute sicher eine der größten verteilten Datenbanken
auf der Welt, die noch dazu auf der ganzen Welt verteilt ist.
Im Bereich der Büroautomatisierung haben verteilte Datenbanken ebenfalls
ihren Einsatz gefunden ([15]).
Bewertung
Verteilte Datenbanken wurden von der Forschung und Wirtschaft als auch vom
Militär mit Begeisterung aufgenommen. Es gab zwar einen kurzen Einbruch
in der Euphorie, als die verteilten Datenbanken die an sie gestellten Forderungen
doch nicht so perfekt erfüllen konnten. Mit der schnellen Weiterentwicklung
der Technik, vor allem der Hardware (Speicher, Datenkommunikation), konnte man
vielen Problemen bald leichter beikommen ([2]).
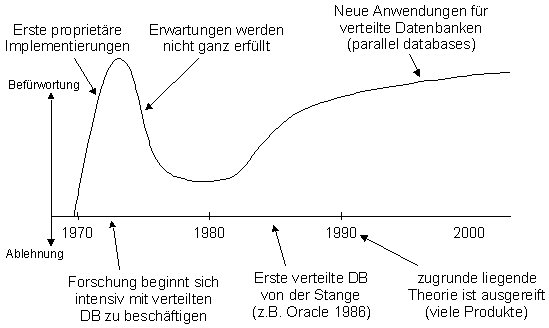
Verteilte Datenbanken sind von damals bis heute ein Renner und werden es sicher
auch noch in Zukunft sein ([12]).
Der Schwerpunkt der verteilten Datenbanken wird sich in Zukunft aber noch mehr
in Richtung Parallel Databases verlagern.
Quellennachweis
- T. Houbé: Verteilte Datenbanken im Kommunikationssystem
der Finanzverwaltung des Landes Nordrhein-Westfalen, 1978
- G. A. Campine: Six Approaches to Distributed Data Bases,
1977
- James
B. Rothnie, Nathan Goodman: A Survey of Research and Development in Distributed
Database Management, 1977
-
Michael Stonebraker: Retrospectation on a Database System, 1979
- Stefano Ceri, Guiseppe Pelagatti: Distributed Databases,
1985
- Hermann Kudlich: Verteilte Datenbanken, 1992
- The History
of DNS
- Die
Produktfamilie von ORACLE
- Die
Informix Produktfamilie bei IBM
- Die
Ingres-Datenbank von Computer Associates
- SESAM/SQL-Server
von Siemens
- James
N. Gray: Database Systems - A Textbook Case of Research Paying Off
- Wolfgang
Becker: Dynamic Load Distribution in Parallel and Distributed Data Intensive
Applications, 1997
- Gruppe
8: Klassische Datenbanken - Warum Relational?
- Gruppe
7: Büroautomatisierung - konzeptionelle Entwicklungen und Auswirkungen
- Gruppe
8: Klassische Datenbanken - Edgar "Ted" Codd
- Foto von
Chris Date
- Gruppe
8: Klassische Datenbanken - Historische Entwicklung
- Gruppe
6: Wissensakquisition - Entstehungskontext