fit 2002 > Programmmiersprachentypen > Konzepte und Techniken > deklarative Sprachen
Überblick
- Willi hat Bauchweh.
- Willi hat Waschmittel gegessen.
- Waschmittel ist giftig.
Ein Beispiel für eine nicht in sich geschlossene Aussage ist:
- Person A hat einen grünen Hut auf.
Diese Aussage ist nicht in sich geschlossen, weil die Person A nicht näher bestimmt ist.
Aus den obigen elementaren Aussagen, können durch logische Verknüpfungen weitere Aussagen gebildet werden:
- Willi hat Bauchweh und Waschmittel ist giftig.
- Wenn Willi Waschmittel gegessen hat und Waschmittel giftig ist, dann hat Willi Bauchweh.
Der Wahrheitswert einer komplexen Aussage ist dabei durch die Wahrheitswerte der in der Verknüpfung auftretenden elementaren Aussagen und Bildungsregeln für die Wahrheitswerte bei logischen Verknüpfungen festgelegt. Die elementaren Aussagen, aus denen weitere, komplexere Aussagen gebildet werden, nennt man auch Atome.
Die Menge von Aussagen über A ist die kleinste Menge von Formeln ![]()
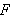 , die folgende Bedingungen erfüllen:
, die folgende Bedingungen erfüllen:
- Jedes Atom ist in

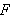 .
.
- Wenn
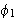 ,
, 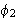 Formeln aus
Formeln aus 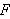 sind, dann sind auch
sind, dann sind auch
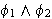 (Konjunktion, und)
(Konjunktion, und)
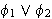 (Disjunktion, oder)
(Disjunktion, oder)
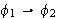 (Implikation)
(Implikation)
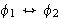 (Äquivalenz)
(Äquivalenz)
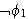 (Negation)
(Negation)
ebenfalls in
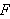 (Die Formeln in
(Die Formeln in 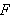 heißen oft auch wohlgeformt).
heißen oft auch wohlgeformt).
Die Semantik von Formeln der Aussagenlogik wird durch Interpretationen und Modelle festgelegt. In der Abstraktion kann dabei jede atomare Aussage ![]()
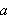 entweder den Wert wahr (t, true) oder falsch (f, false) annehmen.
entweder den Wert wahr (t, true) oder falsch (f, false) annehmen.
Eine Interpretation ist eine Abbildung
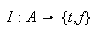
die jedem Atom ![]()
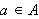 einen Wahrheitswert
einen Wahrheitswert ![]()
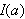 zuordnet. Die Menge aller möglichen Interpretationen wird mit
zuordnet. Die Menge aller möglichen Interpretationen wird mit ![]()
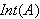 bezeichnet. Der Wahrheitswert einer komplexen Aussage
bezeichnet. Der Wahrheitswert einer komplexen Aussage ![]()
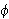 bezüglich einer Interpretation
bezüglich einer Interpretation ![]()
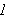 , geschrieben
, geschrieben ![]()
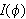 , läßt sich rekursiv aus den Wahrheitswerten der verknüpften Teilaussagen bestimmen. Die Konjunktion von zwei Teilaussagen
, läßt sich rekursiv aus den Wahrheitswerten der verknüpften Teilaussagen bestimmen. Die Konjunktion von zwei Teilaussagen ![]()
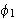 und
und ![]()
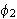 liefert beispielsweise genau dann wahr, wenn
liefert beispielsweise genau dann wahr, wenn ![]()
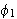 und
und ![]()
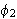 wahr sind, sonst liefert die Konjunktion false. Analoge Regeln gelten auch für Disjunktion, Implikation, Äquivalenz und Negation.
wahr sind, sonst liefert die Konjunktion false. Analoge Regeln gelten auch für Disjunktion, Implikation, Äquivalenz und Negation.
Eine Interpretation ![]()
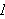 wird genau dann als Modell für eine Aussage
wird genau dann als Modell für eine Aussage ![]()
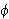 bezeichnet, wenn
bezeichnet, wenn ![]()
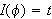 gilt (Notation:
gilt (Notation: ![]()
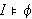 ). Die Menge aller Modelle von
). Die Menge aller Modelle von ![]()
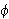 wird mit
wird mit ![]()
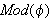 bezeichnet.
bezeichnet.
Weitere Arten von Aussagen können folgendermaßen beschrieben werden:
- Tautologie: Eine Aussage
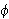 ist eine Tautologie, wenn jede Interpretation ein Modell von
ist eine Tautologie, wenn jede Interpretation ein Modell von 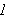 ist (d.h.
ist (d.h. 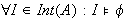 , bzw.
, bzw. 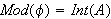 ).
).
- Kontradiktion: Eine Aussage
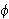 ist widersprüchlich (eine Kontradiktion), wenn keine Interpretation ein Modell von
ist widersprüchlich (eine Kontradiktion), wenn keine Interpretation ein Modell von 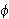 ist (d.h.
ist (d.h. 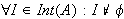 , bzw.
, bzw. 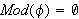 ).
).
- Erfüllbare Aussage: Eine Aussage
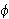 ist erfüllbar, wenn sie ein Modell besitzt (d.h.
ist erfüllbar, wenn sie ein Modell besitzt (d.h. 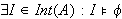 , bzw.
, bzw. 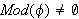 ).
).
Prädikatenlogik
Die Prädikatenlogik stellt wesentlich stärkere Ausdrucksmittel zur Verfügung als die Aussagenlogik. Deshalb ist sie auch für die logische Programmierung wesentlich interessanter und kommt hier (oft mit bestimmten Abwandlungen, Modifikationen und Erweiterungen zum Einsatz). Gegenstand des Interesses sind hier Objekte und deren Eigenschaften sowie Beziehungen zueinander. Aus elemtaren Aussagen über Eigenschaften und Beziehungen von Objekten können durch logische Verknüpfungen (ähnlich wie in der Aussagenlogik) komplexere Aussagen gebildet werden. Objekte bleiben mitunter unbestimmt und werden durch einen Platzhalter (Variable) repräsentiert (z.B. ![]()
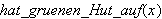 ). Über logische Quantoren kann die Betrachtung einer Aussage für bestimmte Belegungen der Variablen ausgedrückt werden (z.B.
). Über logische Quantoren kann die Betrachtung einer Aussage für bestimmte Belegungen der Variablen ausgedrückt werden (z.B. ![]()
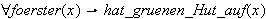 ).
).
Syntax der Prädikatenlogik
Ausgangspunkt für die Bildung von Formeln in der Prädikatenlogik ist ein Vokabular für Objekte, Eigenschaften und Beziehungen, sowie ein Satz von logischen Grundzeichen. Üblicherweise ist folgendes Vokabular vorhanden:
Konstantensymbole
Mit einem Konstantensymbol, z.B. ![]()
 , wird ein bestimmtes Objekt angesprochen, das symbolisch als
, wird ein bestimmtes Objekt angesprochen, das symbolisch als ![]()
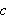 bezeichnet wird. Um eine Formel, in der
bezeichnet wird. Um eine Formel, in der ![]()
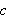 auftritt, auswerten zu können, muss vorher festgelegt sein, welches Objekt durch
auftritt, auswerten zu können, muss vorher festgelegt sein, welches Objekt durch ![]()
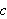 bezeichnet ist (d.h.,
bezeichnet ist (d.h., ![]()
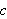 muss interpretiert werden).
muss interpretiert werden).
Funktionssymbole
Ein Funktionssymbol ![]()
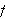 der Stelligkeit
der Stelligkeit ![]()
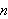 steht intuitiv für eine Funktion, die jeder Eingabe von Objekten
steht intuitiv für eine Funktion, die jeder Eingabe von Objekten ![]()
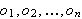 als Ausgabe genau ein Objekt
als Ausgabe genau ein Objekt ![]()
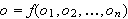 zuordnet.
zuordnet.
Variablensymbole
Ein Variablensymbol (z.B. ![]()
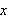 ) steht für ein Objekt, das zur Auswertung einer Formel festgelegt werden muss. Anders als bei einem Konstantensymbol kann hierauf auch ein Quantor angewendet werden.
) steht für ein Objekt, das zur Auswertung einer Formel festgelegt werden muss. Anders als bei einem Konstantensymbol kann hierauf auch ein Quantor angewendet werden.
Prädikatensymbole
Ein Prädikatensymbol der Stelligkeit ![]()
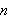 steht für ein
steht für ein ![]()
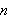 -äres Prädikat. Bei
-äres Prädikat. Bei ![]()
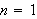 ist dies eine Eigenschaft eines Objektes (z.B.
ist dies eine Eigenschaft eines Objektes (z.B. ![]()
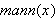 ,
, ![]()
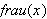 ), bei
), bei ![]()
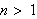 eine Beziehung zwischen Objekten (z.B.
eine Beziehung zwischen Objekten (z.B. ![]()
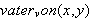 ). Oft werden auch nullstellige Prädikate zugelassen.
). Oft werden auch nullstellige Prädikate zugelassen.
Terme
Terme bezeichnen Objekte und sind intuitiv wie folgt definiert:
Jedes Konstantensymbol ![]()
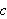 und jedes Variablensymbol
und jedes Variablensymbol ![]()
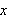 ist ein Term.
ist ein Term.
Wenn ![]()
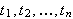 bereits erhaltene Terme sind und
bereits erhaltene Terme sind und ![]()
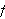 ein
ein ![]()
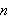 -stelliges Funktionssymbol, dann ist auch
-stelliges Funktionssymbol, dann ist auch ![]()
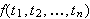 ein Term.
ein Term.
Atomare Formeln
Wenn ![]()
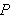 ein
ein ![]()
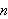 -stelliges Prädikatensymbol ist, und
-stelliges Prädikatensymbol ist, und ![]()
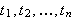 Terme sind, dann ist
Terme sind, dann ist ![]()
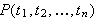 eine atomare Formel (kurz: Atom).
eine atomare Formel (kurz: Atom).
Die Menge der Formeln über dem beschriebenen Vokabular wird nun wie folgt definiert:
Jede atomare Formel ist eine Formel in ![]()
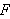 .
.
Wenn ![]()
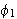 und
und ![]()
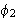 Formeln in
Formeln in ![]()
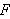 sind und
sind und ![]()
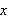 eine Variable ist, dann sind
eine Variable ist, dann sind
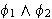
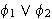
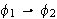
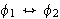
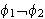
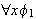 (Allquantifizierung)
(Allquantifizierung)
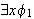 (Existentielle Quantifizierung)
(Existentielle Quantifizierung)
ebenfalls Formeln in ![]()
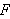 . Die Formel
. Die Formel ![]()
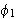 ist dabei der Bindungsbereich des Quantors
ist dabei der Bindungsbereich des Quantors ![]()
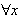 bzw.
bzw. ![]()
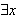 .
.
Klauseln
Klauseln und speziell Horn-Klauseln (benannt nach dem Logiker A. Horn) sind sehr wichtig für die logische Programmierung. Bevor wir uns genau ansehen können, was Horn-Klauseln genau sind, sind einige andere Begriffe zu erläutern:
Satz
Ein Satz ist eine Formel ohne freie Variablen. Er stellt eine in sich geschlossene Aussage dar, die wahr oder falsch sein kann. Ein Satz wird auch als geschlossene Formel bezeichnet.
Literal
Ein Literal ist eine Atomformel (positives Literal) oder deren Negation (negatives Literal).
Klausel
Eine Klausel ist eine Disjunktion ![]()
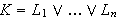 von Literalen
von Literalen ![]()
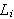 .
.
Konjunktive Normalform (KNF)
Ein Satz ![]()
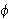 ist in konjunktiver Normalform, wenn er von der Gestalt
ist in konjunktiver Normalform, wenn er von der Gestalt ![]()
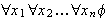 ist, wobei
ist, wobei ![]()
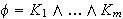 , eine Konjunktion von Klauseln
, eine Konjunktion von Klauseln ![]()
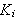 ist.
ist.
Horn-Klausel
Eine Horn-Klausel ist eine Klausel, in der höchstens ein positives Literal vorkommt.
Kalküle
In der Logik wird ein semantischer Folgerungsbegriff definiert, der meist nicht ausreicht, um für gegebene ![]()
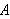 und
und ![]()
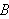 algorithmisch zu bestimmen, ob
algorithmisch zu bestimmen, ob ![]()
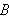 wirklich aus
wirklich aus ![]()
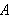 folgt. Um das zu realisieren benötigt man einen geeigneten Kalkül. Ein Kalkül definiert kurz gesagt syntaktische Ableitungen aus Manipulationen von Formeln. Mittels eines Kalküls kann also durch reine Symbolmanipulation aus einer Formel
folgt. Um das zu realisieren benötigt man einen geeigneten Kalkül. Ein Kalkül definiert kurz gesagt syntaktische Ableitungen aus Manipulationen von Formeln. Mittels eines Kalküls kann also durch reine Symbolmanipulation aus einer Formel ![]()
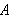 eine Formel
eine Formel ![]()
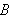 gewonnen bzw. hergeleitet werden, wobei die Bedeutung der in
gewonnen bzw. hergeleitet werden, wobei die Bedeutung der in ![]()
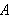 und
und ![]()
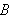 vorkommenden Symbole überhaupt keine Rolle spielt. Trotzdem soll aber ein syntaktisch aus
vorkommenden Symbole überhaupt keine Rolle spielt. Trotzdem soll aber ein syntaktisch aus ![]()
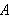 abgeleitetes
abgeleitetes ![]()
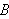 folgen. Wichtige Eigenschaften eines Kalküls sind:
folgen. Wichtige Eigenschaften eines Kalküls sind:
- Korrektheit: Ein Kalkül heißt korrekt, wenn sich durch Ableitung von vorhandenen Formeln nur weitere Formeln ergeben, die auch logisch aus den ersteren folgen.
- Vollständigkeit: Ein Kalkül heißt vollständig, wenn umgekehrt alles, was logisch aus Formeln folgt, eben aus diesen Formeln Abgeleitet werden kann.
Inferenz
Inferenz spielt für die Logik-Programmierung eine wichtige Rolle. Unter Inferenz versteht man die Ableitung von Schlussfolgerungen aus gegebenen Informationen oder Prämissen. Dabei spielt in der Logik-Programmierung natürlich auch die Effizenz von Ableitungensmechanismen eine wichtige Rolle. Prinzipiell gibt es zwei verschiedene Vorgehensweisen in der Ableitung von Formeln:
- Vorwärtsverkettung: Bei der Vorwärtsverkettung wird ausgehend von den Daten weiteres Wissen abgeleitet.
- Rückwertsverkettung: Bei der Rückwertsverkettung dagegen wird das gewünschte Ziel der Herleitung berücksichtigt. Es wird also praktisch von den gesuchten Formeln ausgegangen.
Allgemein lässt sich sagen, dass logikorientierte Programmiersprachen eher den 2. Ansatz, die Rückwertsverkettung, verwenden. Das liegt vor allem daran, dass hier das Ziel der Ableitung berücksichtigt wird und so auch bei einer großen Datenbasis schneller Lösungen gefunden werden können.
Unifikation
Ein wichtiger Begriff, der hier ebenfalls erwähnt werden sollte ist die Unifikation. Fast alle logikorientierten Programmiersprachen erzeugen ihre Resultate (den Output) durch wiederholte Anwendung von Regeln und Unifikation. Die Unifikation wird dabei immer auf die Köpfe von Regeln angewendet. Genauer funktioniert diser Algorithmus folgendermaßen: Die aktuelle Anfrage und der Kopf der angewandten Regel werden Unifiziert. Dann wird die Anfrage durch die Prämissen (die Bedingungen) der Regel ersetzt. Allerdings werden die Variablen in den Prämissen entsprechend der Substitution, die sich aus der durchgeführten Unifikation ergibt ebenfalls ersetzt. Das Ergebnis ist eine neue Anfrage, die im nächsten Schritt wieder den eben beschriebenen Prozess durchläuft. Der Algorithmus terminiert dann, wenn alle auftretenden Anfragen mit Fakten aus dem logischen Programm unifiziert werden konnten. Es wurden somit alle Bedingungen erfüllt und die Anfrage kann als true bewertet werden. Falls eine Unifikation nicht durchgeführt werden kann, muss mittels Backtracking zurückgegangen werden um dann andere Regeln anwenden zu können, die möglicherweise zu einem Ergebnis führen. Falls alle Möglichkeiten ausgereizt wurden und alle Unifikationen scheitern, dann muss die ursprüngliche Anfrage mit false bewertet werden. Sehr wohl kann es auch passieren, dass der beschriebene Algorithmus nie terminiert. Dieser Fall muss vom Programmierer berücksichtigt werden!
Prolog
Allgemeines
Die logische Programmierung hat eine ihrer Wurzeln im Versuch, logische Theoreme mechanisch zu beweisen, z.B. aus den logischen Axiomen
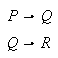
das Theorem
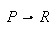
mit Hilfe eines Theorembeweisers abzuleiten.
Bei diesen Untersuchungen stiess man auf folgende Analogie. Die Menge der logischen Axiome kann als ein Programm betrachtet werden, da zu beweisende Theorem als Aufruf des 'logischen' Programms und der Theorembeweiser als Interpreter des Programms. Während des Beweises werden Variablen an Werte gebunden, die als Resultate des Programmaufrufs verstanden werden können; der Beweis ist konstruktiv.
Diese Analogie ist umso fruchtbarer, also auch Probleme aus anderen Bereichen als Theoreme interpretiert werden können, die aus Axiomen zu beweisen sind, z.B. arithmetische Aufgaben.
Ist es wahr, dass ![]()
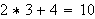 ist?
ist?
oder
Welchen Wert muss ![]()
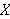 annehmen, damit
annehmen, damit ![]()
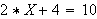 wahr wird?
wahr wird?
Die Axiome sind in diesem Fall die arithmetischen Regeln. Beim Beweis der zweiten Aufgabe wird die Variable ![]()
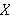 an den Wert
an den Wert ![]()
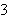 gebunden; das Resultat wurde quasi während des Beweises berechnet.
gebunden; das Resultat wurde quasi während des Beweises berechnet.
Auch Anfagen an eine Datenbank können als Theoreme verstanden werden, z.B. die Anfrage an eine Datenbank mit Fluginformationen
Ist es whar, dass Zürich und New York durch den Flug ![]()
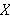 verbunden sind?
verbunden sind?
Die Informationen der Datenbank übernehmen dabei die Rolle der Axiome. Die Variable ![]()
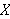 wird wieder während des Beweises bestimmt.
wird wieder während des Beweises bestimmt.
Aus diesem Verständnis von Logik als Programmiersprache ist ein neues Gebiet der Informatik mit intesiver Forschungstätigkeit und einer stetig wachsenden Zahl von Anwendungen entstanden.
Eine Programmiersprache soll ausdrucksstark und effizient sein. Diese Forderungen stehen allerdings oft in Konflikt miteinander. Prädikatenlogik ist eine mächtige und ausdrucksstarke Sprache, Theorembeweiser für Prädikatenlogik sind jedoch notorisch ineffizient. Um aus Prädikatenlogik die praktikable und effiziente Programmiersprache Prolog zu entwickeln, hat man daher den Sprachumfang eingeschränkt. Prolog besteht nur aus einer Teilmenge der Prädikatenlogik, den sogenannten Horn-Klauseln. Diese Teilmenge ist jedoch immer noch mächtig genug, um alle berechenbaren Funktionen zu berechnen. Ausserdem enthält Prolog zusätzliche Systemprädikate, die Operationen des Computers zur Verfügung stellen. Durch diese Systemprädikate wird der Sprachumfang über die Prädikatenlogik hinaus erweitert.
Zum Problemlösen verwendet Prolog Resolution, eine Form der logischen Inferenz. Auch für die Resolution gilt der Gegensatz von Mächtigkeit und Effizienz. Resolution ist mächtig, da sie viele andere Inferenzmethoden subsumiert. In uneingeschränkter Form ist Resolution aber nicht effizient, da Theoreme ungezielt abgeleitet werden und immer die Gefahr der kombinatorischen Explosion besteht. Die Verbindung von Resolution mit Refutation, d.h. mit dem Beweis durch Widerspruch, macht Resolution zielgerichtet. Die Verbindung mit einer einschränkenden Resolutionsstrategie verhindert die kombinatorische Explosion. Allerdings mit dem unerwünschten Nebeneffekt, dass Prolog unvollständig ist, d.h. es kann vorkommen, dass der Prolog-Interpreter existierende Lösungen nicht findest.
Wissen kann im Programmen implizit der explizit vorhanden sein. Im folgenden Modula-Programm ist das Wissen, wie man das Maximum zweier Zahlen bestimmt, implizit enthalten.
PROCEDURE maximum(x,y: INTEGER): INTEGER;
BEGIN
IF X >= y THEN
RETURN x
ELSE
RETURN y
END
END maximum.
Das Wissen ist als Folge von Anweisungen gespeichert, die das Programm nacheinander ausführt. Das auf diese Weise dargestellte Wissen wird erst sichtbar, wenn wir das Programm ablaufen lassen. Die Bedeutung jeder einzelnen Anweisung, der Wert jeder Variablen, kann nicht für sich, sondern nur im Kontext verstanden werden. Es fehlt die sogenannte referentielle Transparenz. In dieser Weise dargestelltes Wissen wird prozedural genannt, da es fest mit der Prozedur verbunden ist.
Das Wissen in Tabellen oder in Datenbanken ist dagegen explizit. Genauso ist das Wissen, wie man das Maximum zweier Zahlen bestimmt, explizit im folgenden Prolog-Programm enthalten.
% maximum(X, Y, MAX) :- MAX is the maximum of X and Y maximum(X, Y, X ) :- X >= Y. maximum(X, Y, Y ) :- X < Y.
Das Prolog-Programm besteht aus einer Kommentarzeile, die mit % beginnt, und zwei Klauseln
![]()
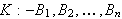 .
.
die wird als logische Implikation interpretieren.
Die Konsequenz K gilt, wenn die Voraussetzungen ![]()
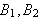 ...und
...und ![]()
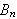 gelten.
gelten.
Beispielsweise besagt die Klausel
maximum{X, Y, Y) :- X < Y.
dass ![]()
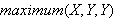 wahr ist, d.h.
wahr ist, d.h. 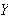 das Maximum von
das Maximum von ![]()
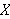 und
und ![]()
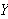 darstellt, wenn die Bedingung
darstellt, wenn die Bedingung ![]()
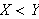 gilt.
gilt.
Jede der beiden Klauseln macht eine Aussage über das Maximum zweier Zahlen, die unabhängig von der anderen Klauses wahr ist. Die referentielle Transparenz ist gegeben.
Die beiden Klauseln zusammen definieren das Maximum zweier Zahlen. Das Programm macht jedoch keine Aussage über eine Ausführungssequenz. Tatsächlich ist die Reihenfolge der beiden Klauseln beliebig. Das Prolog-Programm ist eine zeitunabhängige, wahre Aussage bezüglich seiner drei Argumente.
Das dritte Argument kann als Eingangs- wie als Ausgangsparameter dienen, d.h. wir können mit dem gleichen Programm das Maximum zweier Zahlen bestimmen, aber auch feststellen, ob eine Zahl das Maximum von zwei anderen ist. Viele Prolog-Programme haben die Eigenschaft, dass sie in verschiedener Weise verwendet werden können und dass sie umkehrbar sind.
Diese Darstellung des Wissen wird deklarativ genannt, denn das Wissen ist expliziten, statischen Deklarationen enthalten. Es gibt mehrere Gründe, Wissen deklarativ anstatt prozedural darzustellen.
Deklaratives Wissen kann leichter als prozedurales geändert werden. Normalerweise betrifft wegen der referntiellen Transparenz eine Änderung deklarativen Wissens nur wenige genau lokalisierte Deklarationen, während eine kleine Änderung prozeduralen Wissens häufig eine grosse Änderung der betroffenen Prozeduren nach sich zieht.
Deklaratives Wissen kann -- wiederum wegen der referentiellen Transparenz -- für verschiedene Zwecke verwendet werden, auch für Zwecke, die man ursprünglich nicht vorgesehen hatte. Insbesondere kann aus deklarativen Wissen durch Inferenz anderes nicht explizit dargestelltes Wissen abgeleitet werden. Deklaratives Wissen erleichtert auch die Selbstinspektion von Programmen, d.h. die Fähigkeit eines Programms, über sich selbst Auskunft zu geben oder sich selbst modifizieren zu können.
Prolog-Programme werden durch den Prolog-Interpreter ausgeführt. Das bringt notwendigerweise eine Ausführungssequenz mit sich. Die Klausel
![]()
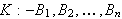 .
.
wird vom Prolog-Interpreter quasi als die Definition einer Prozedur ![]()
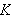 verstanden, die andere Prozeduren
verstanden, die andere Prozeduren ![]()
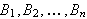 aufruft.
aufruft.
Um ![]()
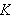 zu beweisen, beweise
zu beweisen, beweise ![]()
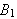 , dann
, dann ![]()
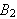 , dann ...dann
, dann ...dann ![]()
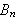 .
.
Diese Interpretation eines Prolog-Programms durch den Prolog-Interpreter wird prozedural genannt. Ein Prolog-Programm hat also sowohl eine deklarative wie eine prozedurale Interpretation. Da der Prolog-Interpreter eine Strategie verwendet, die Prolog unvollständig macht, können die deklarative und die prozedurale Interpretation voneinander abweichen.
Oft kann man für ein Problem ein rein deklaratives Prolog-Programm schreiben, das unabhängig von der Ausführung durch den Prolog-Interpreter war ist, und ein zweites, prozedurales, das Wissen über das Vorgehen des Interpreters verwendet. Die deklarative Darstellung ist lesbarer, aber im allgemeinen weniger effizient als die prozedurale.
Reines Prolog
In Prolog gibt es nur einen Datentype, den Term. Konstantensymbole stehen für Objekte und Prädikatssymbole (Prädikatsnamen) für Relationen (Prädikate) zwischen Objekten bezeichnen. Symbole beginnen in Prolog mit einem kleinen Buchstaben. Prädikate können Argumente haben. Argumente stehen in Klammern und werden durch Kommas getrennt. Jede Zeile eines Programms wird Klausel genannt; sie besteht aus einer Relation gefolt von einem Punkt. Es handelt sich um sogenannte Fakten, d.h. um Klauseln die ohne Bedingungen wahr sind. Die Menge der Klauseln wird Prolog-Programm oder Prolog-Datenbank genannt. Nun kann man Fragen an das Prolog-Programm stellen, indem man diese Fragen als Theoreme formuliert und dann die Theoreme durch den Prolog-Interpreter aus den Axiomen beweisen lässt.
Interessanter wird es, wenn man in den Fragen Variablen einführt, also sozusagen offene Fragen gestellt werden. Variablennamen beginnen mit einem grossen Buchstaben oder mit "_".
Die Variablen stehen am Anfang für ein unspezifiziertes Objekt und werden während des Beiweises an Konstanten gebunden, sodass das Ziel eine logische Konsequenz der Programmaxiome ist. Prolog geht dabei so vor, dass es das Programm von oben nach unten durchläuft und jeweils schaut, ob es eine Variablenbindung gibt, die den Kopf einer der Prolog-Klauseln mit dem syntaktisch zur Deckung bringt.
Wenn es mehrere Möglichkeiten gibt, einer Variablen Werte zuzuweisen, sodass das Ziel jeweils logische Konsequenz des Perogramms ist, wird Prolog auf Wunsch hin eine weitere Bindung nach der anderen vornehmen und eine Lösung nach der anderen generieren. Prozedurale Sprachen sind deterministisch, können jeweils nur eine Lösung berechnen. Prolog ist nicht-deterministisch, denn es kann für ein Ziel eine oder mehrere Lösungen finden, die alle logische Konsequenz des Prolog-Programms sind.
Um komplexere Anfagen stellen zu können bildet man die Konjunktion mehrerer Ziele, die man durch Kommas trennt. Durch solche konjunktive Anfragen können Informationen die nur implizit in der Datenbank enthalten sind gewonnen werden.
parent(Parent,Child) :- father(Parent,Child). parent(Parent,Child) :- mother(Parent,Child).
Wenn nun im Prolog-Programm Fakten mit den Prädikatensymbolen father/2 und mother/2 enthalten sind, dann bekommt man über das Prädikat parent/2 implizit auch diese Information.
Wie geht nun Prolog vor, wenn es Theoreme beweisen will? Wie schon erwähnt, sucht Prolog das Prolog-Programm von oben nach unten nach einer Klausel durch, deren Kopf sich mit dem Ziel decken lässt. Bei konjunktiven Zielen wählt Prolog immer das erste (am weitesten links stehende) Ziel zuerst. Beim Versuch, Ziel und Kopf einer Klausel zur Deckung zu bringen, können Variablen an Werte gebunden werden. Diesen Vorgang nennt man Unifikation. Wurde eine Deckung erreicht, sind also Ziel und Klauselkopf unifizierbar, dann wird die betreffende Programmklausel markiert und das Ziel wird den Körper der markierten Klausel ersetzt. Damit wird ein neues konjunktives Ziel gebildet. Anschliessend werden die gefundenen Variablenbindungen auf das neue konjunktive Ziel angewandt. Gibt es keinen Klauselkopf der sich mit dem Ziel unifizieren lässt beginnt das sogenannte Rücksetzten (backtracking). Prolog verwirt die Wahl der zuletzt markiereten Programmklausel und macht alle Variablenbindungen rückgängig. Dann Versucht Prolog, das Ziel, das zu dieser Wahl geführt hatte, mit dem Kopf einer anderen Programmklausel zu unifizieren. Dabei beginnt Prolog mit der Suche anschliessend an die zuletzt markierte Klausel.
Ein wichtiges Element von Prolog ist die Möglichkeit Rekursive Regeln zu deklarieren. Rekursive Prädikate bestehen aus einer oder mehreren Grundklauseln, die die elementaren Fälle behandeln, und aus einer oder mehreren rekursiven Klauseln für den allgemeinen Fall. Normalerweise wird zuerst eine rekursive Klausel verwendet. Jeder Rekursionsschritt bedeuten eine Annäherung zu den Grundlösungen, sodass zum Schluss eine der Grundklauseln verwendet wird.
ancestor(X,Y) :- parent(X,Y). ancestor(X,Y) :- parent(X,Z), ancestor(Z,Y).
Im obigen Beispiel wurde die Reihenfolge der Ziele innerhalb der rekursiven Klausel von ancestor mit Bedacht gewählt. Die Umordnung der Ziele in der rekursiven Klausel würde bewirken, dass der Suchbaum verändert würde und einen unendlichen Zweig enthält: die rekursive Klausel ruft sich immer wieder selbst auf, und der Beweis nähert sich nicht mehr der Grundklausel. Solche Klauseln werden linksrekursiv geannt.
Dieses Beispiel zeigt, dass im Suchbaum unendliche Zweige auftauchen können. Das kann auch bedeuten, dass Prolog wegen der Tiefensuche Lösungen nicht findet, die sich rechts vom unendlichen Zweig im Suchbaum befinden, d.h. Prolog ist nicht vollständig.
Die Syntax von Prolog ist sehr einfach gehalten. Die grundlegende Datenstruktur von Prolog ist der Term. Terme sind Konstanten, Variablen oder zusammengesetzte Terme. Konstanten bezeichnen Individuen wie Atome oder Zahlen. Atome sind eine Folge von alphanumerischen Zeichen, die mit einem kleinen Buchstaben beginnt, eine Folge von Sonderzeichen ([ ]), oder eine Folge von Zeichen in einfachen Anführungszeichen.
Variablen bezeichnen (noch) unspezifizierte Individuen -- nicht wie in anderen Programmiersprachen Speicherstellen. Variablennamen bestehen aus einer Folge alphanumerischer Zeichen, die mit einen grossen Buchstaben oder mit \grq _\grq beginnt.
Zusammengesetzte Terme f(t1,t2, ...,tn) bestehen aus einen Funktor und n Termen ti, genannt Argumente. Der Funktor f/n ist gekennzeichnet durch seinen Namen f, der ein Atom ist, und die Zahl n seiner Argumente, seine Arität. Funktoren mit gleichen Namen, aber verschiedener Arität werden als verschieden betrachtet.
Prolog-Ziele sind Atome oder zusammengesetzte Terme. In vielen Prolog-Implementationen können Ziele auch Variablen sein, die jedoch vor der Verwendung instanziert sein müssen.
Volles Prolog
Im reinen Prolog sind alle Prädikate durch eine Menge von Fakten definiert oder verhalten sich so. Die deklarative Interpretation steht im Vordergrund, d.h. Klauseln werden als Implikationen betrachtet. Prädikate haben keine Seiteneffekte. Argumente von Prädikaten können als Eingangs- und als Ausgangsparameter dienen, d.h. Prädikate sind umkehrbar. Die Reihenfolge der Klauseln eines Prädikats bestimmt die Reihenfolge, in der die Lösungen gefunden werden. Die Reihenfolge der Ziele eines Klauselkörpers ist für die Beantwortung von Anfragen unwichtig, solange im Suchbaum keine unendlichen Zweige auftauchen.
Das volle Prolog enthält darüber hinaus sogenannte Systemprädikate, die es zu einer effizienten und vollständigen Programmiersprache machen. Einige Systemprädikate, z.B. die arithmetischen, verwenden Operationen des Computers und sind dadurch effizienter als die entsprechenden Prädikate des reinen Prolog. Andere Systemprädikate haben Effekte, die ausserhalb der Prädikatenlogik liegen, z.B. die Ein- und Ausgabe. Die prozedurale Interpretation spielt eine Rolle und die Reihenfolge von Zielen eines Klauselkörpers und die Reihenfolge der Klauseln eines Prädikates können relevant sein.
Im vollen Prolog existieren Systemprädikate zu folgenden Bereichen:
-
Arithmetik (Auwertung von arithmetischen Ausdrücken wie,
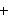 und
und 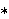 oder auch Vergleichsoperatoren, wie
oder auch Vergleichsoperatoren, wie 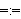 ,
, 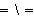 ,
, 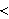 ,
, 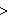 ,
, 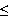 ,
, 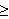 .)
.) -
Extralogische Prädikate (Ein- und Ausgabe)
-
Strukturuntersuchungen (Typenbestimmung, Analyse und Synthese von Termen)
-
Metalogische Prädikate (Test auf Instanzierung, Unifizierbarkeit, Identität)
Prolog stellt weiters das Systemprädikat !/0, ausgesprochen Cut, zur Verfügung, um dynamisch Suchbäume zu beschneiden. Der Cut kann verwendet werden, Zweige des Suchbaums abzuschneiden, von denen man weis, dass sie keine Lösung enthalten. Allerdings kann man mit dem Cut auch Zweige mit Lösungen entfernen. In jedem Fall führt der cut zu effizienteren Lösungen, da der Suchbaum verkleinert wird; sogenannte choice points werden eliminiert und damit der Speicher- und Zeitaufwand verringert.
Es werden grüne und rote Cuts. Grüne Cuts liegen vor, wenn die deklarative Bedeutung nicht verändert wird, d.h. wenn die gleichen Lösungen geliefert werden (im Vergleich zu einer Deklaration ohne Cuts). Verändert ein Cut die Lösungsmenge spricht man von einem roten Cut.
Rote Cuts können benutzt werden, um in Prolog Kontrollstrukturen zu definieren, die in der Anwendung sicherer als der Cut sind.
Prolog-Klauseln erlauben nur die Darstellung positiver Information, d.h. Prolog kann immer nur beweisen, dass etwas der Fall ist, nicht aber dass etwas nicht der Fall ist. Die normale logische Verneinung wird mit ![]()
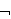 bezeichnet. Das Theorem
bezeichnet. Das Theorem ![]()
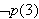 ist keine logische Folgerung des Programms
ist keine logische Folgerung des Programms ![]()
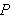
p(1). p(2).
Allerdings wird die Frage
?- p(3).
von Prolog mit No beantwortet, d.h. auch das Ziel ![]()
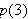 ist keine logische Folgerung des Programms
ist keine logische Folgerung des Programms ![]()
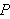 . Aus
. Aus ![]()
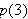 folgt nicht aus
folgt nicht aus ![]()
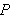 , folgt
, folgt ![]()
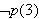 gilt, wird closed world assumption genannt. Wenn ein variablenfreies Ziel
gilt, wird closed world assumption genannt. Wenn ein variablenfreies Ziel ![]()
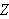 nicht aus einem Programm
nicht aus einem Programm ![]()
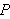 folgt, wird
folgt, wird ![]()
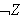 geschlossen, d.h. es wird angenommen, dass das Programm
geschlossen, d.h. es wird angenommen, dass das Programm ![]()
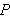 alle Informationen über das betreffende Gebiet enthält.
alle Informationen über das betreffende Gebiet enthält.
Prolog-Programmiertechniken
Wie in jeder Programmiersprache haben sich auch in Prolog eine Anzahl von Programmiertechniken entwickelt, von denen hier beispielhaft Schleifen vorgestellt werden.
Da es in Prolog keine Iteration gibt, müssen Backtracking oder Rekursion verwendet werden, um iterative Algorithmen zu implementieren.
Failure-Driven Loop
Eine wichtige Schleifenkonstruktion ist die Failure-Driven Loop, mit der man alle Lösungen eines Ziels generieren kann. Meistens endet sie mit dem Systemprädikat fail, das immer misslingt und dadruch Backtracking auslöst.
%echo :- echo read terms from the standard input and echos %them on the standard output echo :- repeat, read(X), echo(X). echo(X) :- X == end_of_file. echo(X) :- write(X), nl, fail.
Anstelle durch das Prädikat fail kann man die Schleife auch durch andere Prädikate abschliessen, die im Normalfall fehlschlagen, zum Abschluss jedoch gelingen.
Generate and Test
Viele Algorithmen lassen sich in zwei Teile aufteilen: in einen Generator, der Lösungen produziert oder vorschlägt, und einen Tester, der vorgeschlagene Lösungen auf Gültigkeit prüft.
generate_and_test(X) :- generate(X), test(X).
Algorithmen die auf diesem Generate and Test Prinzip basieren, sind übersichtlich und meistens leichter als andere Algorithmen zu finden. Sie sind allerdings oft nicht sehr effizient, denn der Generator kann zuviele Lösungen vorschlagen, die der Tester verwirft. Das Ziel ist es dann, den Generator und den Tester so miteinander zu kombinieren, dass nur noch akzeptable Lösungen vorgeschlagen werden.
Schleifen durch Rekursion
Iterative Algorithmen können auch durch Rekursion implementiert werden. Rekursive Algorithmen sind meistens eleganter als iterative, d.h. allgemeiner verwendbar, kürzer und leichter zu verstehen, haben jedoch oft den Nachteil der geringeren Effizienz.
%echo :- echo read terms from the standard input and echos%them on the
%standard output echo :- repeat, read(X), echo(X). echo(X) :- X == end_of_file. echo(X) :- write(X), nl, read(Y), echo(Y).
Zählende Schleife
Mit zählenden Schleifen kann man z.B. alle Argumente eines Terms untersuchen. Allgmein hat eine solche Schleife, in diesem Fall eine abwärtszählende, folgende Form:
predicate(arguments) :- % initialize ..., predicate(N,arguments). predicate(N,arguments) :- process(N,arguments), % process N'th element NM1 is N-1, predicate(NM1,arguments).
Weiterführende Informationen
>[paradigm] The Logic Programming Paradigm and Prolog (paper)
>[programming] Logic Programming Introduction
>Entstehungskontext | Konzepte und Techniken | Entwicklung und Auswirkungen | Praxis | Bewertung