fit 2002 » Programmiersprachen und Konzepte » 4th Generation Languages
Fourth Generation Languages, oder übersetzt „Sprachen der vierten Generation“, sind wie der Name bereits andeutet eine Weiterentwicklung von Third Generation Languages. Um die Namensgebung und die Weiterentwicklung auf dem technischen Aspekt besser zu verstehen, ist ein kleiner Exkurs nötig:
Computer werden dazu gebaut um Informationen zu speichern, zu akquirieren und zu verarbeiten. Üblicherweise können sie Information nur in Form von elektronischen Signalen verarbeiten, die als Binäre Zahlen dargestellt werden können.
Programmiersprachen dienen dazu dem Programmierer zu unterstützen und agieren sozusagen als Dolmetscher von einer dem Programmierer verständlicheren Sprache in Maschinensprache.
Der Programmierer könnte seine Programme anstatt in einer höheren Programmiersprache direkt in Maschinensprache schreiben. Der große Vorteil an höheren Programmiersprachen jedoch ist, das sie der menschlichen Sprache ähnlicher sind und somit für den Menschen einfacher und verständlicher.
Generell kann man sagen, je ähnlicher die Programmiersprache der menschlichen Sprache ist, desto höher entwickelt ist sie.
Deshalb ist es möglich verschiedene Programmiersprachen zu betrachten und sie in unterschiedliche Kategorien - beziehungsweise bei Programmiersprachen spricht man von Generationen, einzuteilen.
First Generation Language:
First Generation Language oder Machine Language, ist die ursprünglichste Form und besteht praktisch aus Binärcode also 0en und 1en. Dieser war auf verschiedensten Medien, typischerweise Lochkarten codiert mit denen man den Computer „füttern“ konnte.
Diese Sprache war natürlich sehr unhandlich und schwer für den Menschen verständlich. Die Programmierer mussten wissen welcher Binärcode mit welchem „Befehl“ korrespondiert.
Außerdem war sie computergebunden, da jeder Computer oder Prozessor seine eigene Maschinensprache hatte.
Second Generation Languages:
In den frühen 50ern entwickelten Programmierer Maschinen um ihnen einen Teil der Codierungsarbeit abzunehmen, dies wurde automatisches Codieren genannt.
Der nächste Schritt war anstatt mühsamer absoluter Adressierung ein Programm die korrekte Adressierung durchführen zu lassen (man kann also mit relativen Adressen arbeiten), außerdem wurden Wörter und Abkürzungen, auch Mnemonics genannt, für die einzelnen Codes (Kommandos) eingeführt, sogenannte Opcodes.
Genau diese Weiterentwicklung bezeichnet Second Generation Languages, auch Assembly Languages, übersetzt Assemblersprachen genannt.
Für jedes Maschinenkommando, welches der Prozessor versteht, gibt es eine Entsprechung in der dem Prozessor zugehörigen Assemblersprache.
„Assemble“ bedeutet übersetzt zusammensetzen. Die Assemblersprache wird also deshalb so genannt weil sie aus der Abkürzung „ADD R1,R2,R3“, was soviel bedeutet wie addiere den Registerinhalt des Registers 1 zu dem Registerinhalt des Registers 2 und speichere das Ergebnis in Register 3, den richtigen Befehl in Maschinensprache, beispielsweise 0110001001100100 zusammensetzen kann.
Third Generation Languages (3GL) oder Higher Order Languages (HOL):
Der Nächste große Schritt in der Programmiersprachenentwicklung kam 1952 mit der Entwicklung von FORTRAN (Formula Translator).
FORTRAN wurde von IBM von einem Team unter John W. Backus entwickelt und war nur auf ihrer Maschine der IBM 704 lauffähig. Spätere Versionen für andere Computer und Plattformen folgten. Bald wurde FORTRAN, das eigentlich „nur“ aus vordefinierten Instruktionen bestand als Programmiersprache anerkannt weil es folgende Kriterien erfüllte:
Eine Programmiersprache muss
· ein Vokabular – eine Liste von (reservierten) Wörtern
· eine Grammatik – die Syntax
· Eindeutigkeit in den Wörtern und in der Semantik
aufweisen.
FORTRAN war im Gegensatz zur Assemblersprache viel näher an der natürlichen Sprache und ein simples FORTRAN Kommando konnte mehreren komplizierteren Maschinenkommandos entsprechen.
Ein großer Nachteil jedoch war, dass man ein FORTRAN nicht einfach auf jedem Computer laufen lassen konnte. Für jeden Computer, wenn der Prozessor unterschiedlich war musste FORTRAN umgeschrieben werden.
Die Programmiersprache C kam in den Jahren 1969 – 1973 auf und wurde von Dennis Richey und David Kerningham entwickelt, die bei Bell Laboratories arbeiteten.
Das Zauberwort lautete Portabilität, also die Möglichkeit derselbe Code auf verschiedenen Maschinen mit unterschiedlichen Prozessortypen ausführen zu können.
Ein wichtiger Teil von C sind nämlich die sogenannten Libraries oder Programmbibliotheken, die maschinenspezifische Instruktionen für das ausführen von bestimmten Aufgaben enthalten.
Diese Libraries sind der einzige Teil an C der wirklich umgeschrieben oder ergänzt werden muss für verschiedene Maschinen oder Prozessorfamilien. Die Stärke von C liegt jedoch darin, dass die Programmiersprache und das Programmierinterface jedoch gleich bleiben.
Man kann also denselben Sourcecode verwenden, man muss ihn nur auf dem anderen Computer neu kompilieren, beziehungsweise von einem Programm in seine Maschinensprache übersetzen lassen.
Bald erkannte man das neben Portabilität auch die Möglichkeit der Wiederverwendbarkeit des Sourcecodes sehr wichtig für die Entwicklung von Software war.
Die Antwort zu diesem Problem liefert das Konzept der Objekt Orientierten Programmiersprachen, in denen Datenstrukturen und ihre Methoden beziehungsweise Funktionen zu Klassen zusammengefasst werden, welche aufgrund dieser inhärenten Strukturierung und dem Konzept der Vererbung ohne gröbere Änderungen in neuem Code wiederverwendet werden können.
Um den Programmierern die Arbeit zu erleichtern wurden graphische Entwicklungsumgebungen oder Graphische User Interfaces (GUI) entworfen, die den Programmierer unterstützen und ihm einiges an „Handarbeit“ abnehmen.
Aus dieser Entwicklung kann man bereits ein Resümee ziehen was die Generation einer Sprache praktisch über sie aussagt:
Je höher die Generation desto
· strukturierter ist die Sprache
· einfacher ist die Implementation für den Benutzer
· weniger Schreibarbeit ist nötig, da es eingebaute Funktionen gibt welche die Arbeit übernehmen
· mehr Limitierungen gibt es durch die eingebauten Funktionen, welche man jedoch für speziellere Anwendungen umgehen kann, indem man auf eine niedrigere Sprachebene zurückgreift
· weniger systemnah ist die Sprache, d.h. desto weniger Kontrolle hat der Benutzer über die Vorgänge im Computer (den Maschinencode und Bitmanipulation) zur Laufzeit
· schneller ist die Sprache erlernbar
· mehr Debugging und Kontrollmöglichkeiten sind möglich
· „graphischer“ ist die Sprache
Je niedriger die Generation desto
· mehr Instruktionen werden benötigt
· mehr Kontrolle hat der Programmierer über das System
Fourth Generation Languages (4GL) oder Very High Level Languages (VHLL):
Die nächste Erkenntnis, die die Computerindustrie maßgeblich beeinflusst hat war, das die Programmierer fast ebenso lange für das debuggen ihres Codes brauchen, wie für das schreiben selbst. Eine Möglichkeit dieses Problem zu umgehen bieten Fourth Generation Languages.
Die Grundidee der Fourth Generation Languages besteht darin bei Anwendungen anzugeben „WAS“ der Computer machen soll und nicht „WIE“.
Fourth Generation Languages kommen deshalb typischerweise in spezialisierten, abgegrenzten Gebieten zum Einsatz wie zum Beispiel das Abfragen, Verändern und Sichern von Daten einer Datenbank.
Wie oben erwähnt gibt man dabei an welche Daten wo gespeichert oder verändert werden sollen, und muss dem Programm keine Anleitung geben „WIE“ dieser Vorgang vonstatten gehen soll.
Fourth Generation Languages lassen sich grob in vier funktionelle Bereiche unterteilen:
· Query and Report Generators
· Graphic Languages
· Database Management Tools
· Spreadsheets
Wichtige Merkmale von Fourth Generation Languages:
· Die Befehle beziehungsweise die Syntax sind einfacher gehalten und ähneln der natürlichen Sprache noch mehr, als dies bei Third Generation Languages der Fall ist, deshalb sind sie leichter erlernbar.
· Aufgrund des nicht-prozeduralen Aufbaus vieler 4GL’s ist die Technik Aufgaben zu lösen einfacher, während die Resultate beeindruckend sind und schnell berechnet werden.
· Hinter einer Anweisung in einer 4GL können sich 100e Codezeilen einer Sprache von älterer Generation verbergen ohne das der Benutzer darüber bescheid wissen muss.
· 4GL’s werden typischerweise für ein begrenztes Einsatzgebiet entwickelt und haben somit eine begrenzte Zahl an Funktionen oder Anwendungen. Dies macht 4GL’s einerseits benutzerfreundlicher, für den Anwendungszweck effizient und schneller erlernbar, andererseits sind die Möglichkeiten für den Programmierer begrenzt.
· Der Benutzer von 4GL’s muss aufgrund intelligent gewählter Default Options nicht alles selber spezifizieren, sondern der Compiler oder Interpreter trifft Annahmen darüber was der Benutzer braucht.
· In vielen 4GL’s treten Dialoge zwischen dem Benutzer und der Software auf. Sie kann Fragen an den Benutzer stellen, Fehler signalisieren und Inkonsistenten aufscheinen lassen, während die Applikation erstellt wird.
Resümee:
Durch die Benutzung einer 4GL ist es dem Benutzer möglich in einem viel kürzerer Zeitaufwand für Entwicklung und Debugging eine Applikation zu erstellen, als dies mit Programmiersprachen einer älteren Generation möglich wäre.
Es werden weniger Codezeilen benötigt und das Debuggen sowie spätere Änderungen sind leichter durchführbar.
Auch kann ein Kunde viel früher an dem Entwicklungsprozess einer Applikation Einsicht nehmen und selbst aktiv teilhaben, da Simulationsläufe gestartet werden können und vorläufige Ergebnisse beurteilt, lange bevor die Applikation fertig ist.
Die Nachteile liegen auf Seite des Hardwareaufwandes, welchen 4GL’s benötigen. 4GL’s brauchen in der Regel mehr Festplattenplatz, schnellere Prozessoren und mehr Arbeitsspeicher als 3GL’s. Außerdem hat der User selbst normalerweise nicht die Möglichkeit in die Benutzung dieser Ressourcen von der 4GL einzugreifen und ineffiziente Hardwarenutzung zu reduzieren.
Prolog
Die Programmiersprache Prolog wurde 1972 von Alain Colmerauer und Phillipe Roussel an der Universität Marseille entwickelt. Anfänglich wurde Prolog für natürlichsprachige Dialogsysterne und andere Anwendungen im Bereich der künstlichen Intelligenz eingesetzt. Weite Bekanntheit erlangte Prolog, als es Anfang der achtziger Jahre vom japanischen Handels‑ und Industrieministerium (MITI) für die Entwicklung von Systemen der 5. Generation (wissensverarbeitende Systeme) auserkoren wurde. In weiterer Folge verbreitete sich Prolog auch in Europa und den Vereinigten Staaten.
Ausgehend von Prolog gibt es viele Weiterentwicklungen. Die Erweiterungen von Prolog um constraints eröffneten viele neue Anwendungsbereiche. Der Kern der Sprache aber hat sich bewährt und ist unverändert geblieben.
Heute wird Prolog für kommerzielle Anwendungen auch außerhalb der künstlichen Intelligenz eingesetzt. Die folgenden Beispiele zeigen typische Anwendungsbereiche für Prolog.
Automatische Netzwerkkonfiguration. Microsoft Windows NT verwendet Prolog (eingebettet in C++) zur automatischen Netzwerkkonfiguration (applet NCPA.CPL). Aus den Beschreibungen über vorhandene Netzwerktreiber und Karten (NDIS network driver interface specification) ermittelt Prolog eine lauffähige Konfiguration. Entscheidend für Prolog war die rasche Verfügbarkeit eines lauffähigen Prototypen, der innerhalb weniger Tage fertig gestellt wurde.
Intelligente Datenbankschnittstelle. Die Wirtschaftsprüfungs- und Unternehmensberatungsgesellschaft PricewaterhouseCoopers (vormals Price Waterhouse und Coopers & Lybrand) entwickelte das in C, Prolog und Java geschriebene EDGARSCAN (http://edgarscan.tc.pw.com), um auf die von der U.S.‑amerikanischen Securities and Exchange Commission (SEC) verwalteten Unternehmensdatenbank EDGAR, die Quartalssberichte börsennotierender Firmen erfasst, zugreifen zu können. Prolog wird hier zur Analyse der frei strukturierten Geschäftsberichte verwendet.
Produktionsplanung. Der französische Flugzeughersteller Dassault Aviation verwendet zur Produktionsplanung ein in Prolog (um constraints erweitert) geschriebenes decision support system (PLANE), das Lagerkosten und Stehzeiten minimiert.
Juristisches Expertensystem. Zur Vereinfachung der Genehmigung der Ein‑ und Ausfuhren landwirtschaftlicher Produkte verwendet das belgische Wirtschaftsministerium ein in Prolog geschriebenes Expertensystem (EUREX). EUREX begründet Entscheidungen in französischer und flämischer Sprache. Durch EUREX werden ca. 500 Seiten EU‑Recht sowie nationale Regelungen erfasst, die laufend erweitert werden.
Umwelterklärungen. U.S.‑amerikanische Betriebe legen jährlich der Umweltbehörde EPA (environmental protection agency) eine Erklärung über die Verwendung und Entsorgung von Chemikalien vor. Pro Chemikalie ist ein Formular mit 300 Einträgen auszufüllen, wofür bei manueller Bearbeitung drei Arbeitstage anfallen. Größere Betriebe reichen 100 bis 1000 derartige Formulare ein. Durch das in Prolog geschriebene Experten‑Datenbanksystem Syllog reduzierte IBM die Bearbeitungszeit eines Formulars auf eine halbe Stunde. Bei Betriebsprüfungen begründet Syllog jeden Formulareintrag.
Echtzeitexpertensystem. Die japanische Baufirma Toda verwendete für Bohrungen des Tokyo Bay Tunnels ein Expertensystem in Prolog, das alle 10 Sekunden über den Fortgang der Bohrarbeiten berichtet und Korrekturen vorschlägt und begründet.
Datenbanken ‑ legacy system mediation services. Firmen, die EDV seit Jahrzehnten verwenden, verfügen eine Unzahl unterschiedlicher und voneinander unabhängiger Datenbestände, die auf verschiedensten Rechnern existieren (sog. legacy systems). Der Datenaustausch in einer derartigen Umgebung ist äußerst aufwendig, da jeweils eigene Programme zur Datenextrahierung und ‑konvertierung benötigt werden. Der Flugzeughersteller Boeing entwickelte einen in Prolog realisierten mediator zum transparenten Zugriff auf sämtliche Datenbestände.
Multimedia‑CAM. Die japanische Optikerkette Paris Miki verwendet ein prologbasiertes System für Entwurf, Fertigung, Vertrieb und Verkauf maßgeschneiderter Brillen. Prolog entwirft nach dem über eine Videokamera aufgenommenen Kundenbild, ärztlichen Befunden und Kundenwünschen ein Brillenmodell, das probeweise über das Bild des Kunden gelegt wird. Die Maßbrille wird innerhalb einer Stunde gefertigt.
So verschieden die Anwendungen sind, haben sie und viele andere erfolgreiche Prologanwendungen einige gemeinsame Eigenschaften:
· Die Anwendungen bauen auf bestehende Systeme auf. Sie ersetzen nicht bestehende Systeme traditioneller Technologien, sondern erweitern sie um Fähigkeiten, die mittels herkömmlicher Technologien nur schwer zu realisieren sind.
Prolog wird gemeinsam mit anderen Programmiersprachen verwendet. Die graphische Benutzeroberfläche, die Anbindung an Betriebssysteme und Datenbanksysteme wurde in anderen Sprachen realisiert; etwa in C, C++, Wafe, TCL, SQL.
· Die genaue Problemstellung musste erst ausformuliert werden. Zur Validierung von Konzepten mussten Prototypen rasch erstellt werden. Ein exploratives Vorgehen war erforderlich.
· Das Endprodukt musste in sehr kurzer Zeit fertig gestellt werden.
· Während der Systementwicklung veränderten sich die Anforderungen. Die Anwendungen werden ständig erweitert. Die Eingabe neuen Wissens erfolgt durch Personen ohne Programmierkenntnisse (Chemiker, Juristen etc.). Das Wissen wird in spezialisierten Sprachen (also nicht direkt in Prolog) repräsentiert, die ihrerseits in Prolog geschrieben sind.
Der Name Prolog ist ein Kürzel für programmation en logique, Programmieren in Logik. Die grundlegenden Konstrukte von Prolog stammen aus der Logik. Aus diesem Grund wird Prolog als logikorientierte Programmiersprache bezeichnet. In Prolog geschriebene Programme können meist als logische Formeln gelesen werden. Logische Formeln ihrerseits können als einfache deutsche Sätze, die Sachverhalte beschreiben, gelesen werden. Deshalb können auch Prolog‑Programme als deutsche Sätze gelesen werden.
Beim Lesen eines Prologprogramms kann man auf das eigene Sprachgefühl zurückgreifen, um ein Programm zu verstehen oder die Richtigkeit einer Definition zu überprüfen. So klingen die meisten fehlerhaften Programme, wenn man sie laut liest, bereits falsch.
Umgekehrt geht man beim Schreiben eines Programms oft von einer informellen deutschen Beschreibung aus. Durch das Ausformulieren impliziter Annahmen und das Entfernen sprachlicher Zweideutigkeiten und vager Formulierungen gelangt man schrittweise zu einer in Prolog formulierbaren Beschreibung. Im Satz Die Umstrukturierung verhindert die Gewinnmaximierung. ist etwa nicht eindeutig, was wodurch verhindert wird.
Prolog hilft also, wie auch Logik allgemein, Dinge genauer zu analysieren und zu formulieren.
Prolog wird auch als deklarative Programmiersprache bezeichnet, um es imperativen Programmiersprachen gegenüberzustellen. Programme in herkömmlichen Programmiersprachen bestehen aus einer Folge von auszuführenden Befehlen (z.B. Erhöhe x um eins "x := x+l", sende eine Nachricht an ein Objekt).
Herkömmliche Programmiersprachen werden daher imperativ, befehlsorientiert oder auch präskriptiv genannt. In einem imperativen Programm muss man genau angeben, durch welche Schritte man zu dem gewünschten Resultat gelangt. Ein typisches imperatives Programm stellt eine Rechenvorschrift „einen Algorithmus“ dar.
In einer deklarativen Programmiersprache beschreibt man, was das Resultat sein soll. Man vernachlässigt dabei, welche Schritte durchgeführt werden müssen, um zum gewünschten Resultat zu gelangen. Die Details der Ausführung überlässt man der Programmiersprache. Üblicherweise besteht ein Programm in einer deklarativen Programmiersprache nicht aus einer Rechenvorschrift, sondern aus einer Beschreibung, die besagt, was gilt.
Durch den Umgang mit imperativen Programmiersprachen ist man gewohnt, vor allem den Ablauf eines Programms (das Wie) statt die Bedeutung (das Was) zu betrachten. Solange man zu sehr auf das Wie fixiert ist, fällt es schwer, Prologprogramme zu schreiben und zu verstehen. Es ist daher anfangs besonders wichtig, sich auf die Bedeutung eines Programms zu konzentrieren.
Prolog ist nicht nur ein an die Logik angelehnter Formalismus, sondern auch eine universelle Programmiersprache, die zur Lösung von konkreten Problemen eingesetzt wird. Dadurch mussten bei der Entwicklung von Prolog Kompromisse eingegangen werden. Im Gegensatz zu automatischen Beweisern verwendet Prolog etwa nur einen sehr einfachen, dafür aber sehr schnellen Beweismechanismus. Beweise in Prolog sind oft vergleichbar schnell mit der Ausführung eines Programms, das in einer herkömmlichen (imperativen) Programmiersprache geschrieben ist. Die Geschwindigkeit der Ausführung wird aber mit der Unvollständigkeit von Prologs Beweisverfahren bezahlt. Es ist daher bis zu einem gewissen Grad erforderlich, beim Programmieren auf das spezielle Beweisverfahren Rücksicht zu nehmen.
Prolog weist verglichen mit herkömmlichen Programmiersprachen eine sehr geringe Anzahl von Konstrukten auf. Ein Prolog‑Programm besteht aus einer Folge von Horn‑Klauseln. Eine Klausel ist entweder ein Faktum, eine Regel oder eine Anfrage. Fakten und Regeln beschreiben geltende Sachverhalte. Sie stellen die Wissensbasis des Programms dar. Anfragen ermöglichen, dieses Wissen zu verwenden. Im Programmtext wird jedes Faktum, jede Regel und jede Anfrage durch einen Punkt abgeschlossen.
Beispiel:
← kind_von(bart, homer).
← kind_von(homer, marge). % Fehler
SQL
Die relationale Abfragesprache SQL wurde 1974 für das experimentelle Datenbankmanagementsystem System R von IBM entwickelt – SQL wurde damals SEQUEL (Structured English QUEry Language) genannt – und 1986 von ANSI (American National Standards Institute) und 1987 von ISO (International Standard Organisation) als internationaler Standard einer Sprachschnittstelle für relationale Datenbankmanagementsystem genormt.
Nach einer Überarbeitung im 1989, wo die Sprache erweitert wurde, um referenzielle Integrität und generelle Integritätsbedingungen zu verarbeiten, wurden 1992 in der zweiten Überarbeitung die Datenmanipulation, Schemamanipulation und Datendefinitionssprache erweitert. Diese zweite Version des Standards war in den letzten Jahren die Referenz und wird als SQL-2 oder SQL-92 bezeichnet. SQL-2 ist relational vollständig, d.h., alles, was im Relationenkalkül ausdrückbar ist, kann auch in SQL ausgedruckt werden.
Ab 1992 wurde an einer dritten, großen Überarbeitung des Standards gearbeitet, um objekt-orientierte Konzepte, persistente Objekte, Multimedia-Datentypen und temporale Datentypen und Sprachkonzepte zu inkorporieren und SQL zu einer turing-vollständige Sprache (alle berechenbaren Abfragen sind möglich) zu erweitern.
Zu Beginn des Jahres 2000 entwickelte sich das SQL-3 Standard.
Der Schritt von SQL-2 zu SQL-3 bedeutete eine enorme Erweiterung des Sprachumfangs von SQL. Aufgrund des anspruchsvollen und komplexen Programms haben die Normierungsinsitute ANSI und ISO beschlossen, die weitere Entwicklung von SQL in mehrere Standards aufzuteilen.
Zusätzlich zum SQL-3 Projekt gibt es weitere Projekte zur Erweiterung von SQL, die teils neuere Entwicklungen in den Informationssystemen aufgreifen. So hat etwa SQL/MM zum Ziel, Standard-Multimedia-Pakete basierend auf ADT’s in SQL-3 zu entwickeln, und SQL/RT will Unterstützung für Echtzeitdatenbanken geben.
Beispiel algebraische Systeme: Mathematica
Mathematica von Wolfram Research Inc. liegt derzeit in Version 4.0 vor. Die erste Version ist 1988 erschienen. Diese erste 4th GL Sprache für algebraische Berechnung wird von manchen als der Beginn der modernen technischen Mathematiksysteme bezeichnet. Seit den 60er Jahren werden verschiedenste Bibliotheken und Implementierungen von mathematischen Funktionen entwickelt, aber erst seit Mathematica gibt es eine Lösung, die gleichzeitig numerische, graphische und symbolische Berechnung erlaubt, ohne vom Benutzer Programmierkenntnisse vorauszusetzen.
Typisch für den 4th Generation Language Charakter von Mathematica ist die große Anzahl von Schnittstellen zu externen Programmen. Es gibt ein eigenes C Toolkit, mit dem der Mathematica Kernel von anderen Programmen angesprochen werden kann und somit dynamisch Berechnungen generiert werden können. Mit Mathematica lassen sich außerdem wissenschaftliche Dokumente im LaTex-Format erstellen.
Besonders wichtig ist die Einfachheit der Ausdrücke im Vergleich zu herkömmlichen Programmiersprachen. Es gibt zwar für die meisten von ihnen Bibliotheken, die komplexe mathematische Berechnungen erlauben, aber der erstellte Code ist für die numerische Berechnung eines Integrals mit Sicherheit wesentlich umfangreicher als folgender Ausdruck:

Out[3] :=
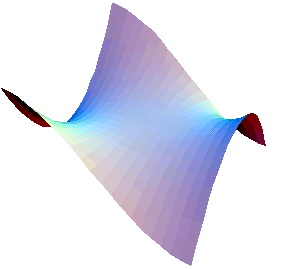
Abbildung 1: Affensattel
Auch wenn man nicht unbedingt über das mathematische Hintergrundwissen verfügt um den Ausdruck zu verstehen, weiß man jedenfalls auf den ersten Blick, dass es sich überhaupt um einen mathematischen Ausdruck handelt, was bei allgemeineren Programmiersprachen nicht unbedingt sein muss. Diese könnten beispielsweise folgende Syntax haben:
NumInteg (-1, 1, "x^^4", "x");
Der Code von Mathematica ist in diesem Fall nicht nur wesentlich lesbarer, er ist leichter wartbar und kompakter. Da es eine weit verbreitete wissenschaftliche Applikation ist, kann man im allgemeinen davon ausgehen, dass die Berechnungen effizienter durchgeführt werden als bei den meisten Libraries. Mathematica steht (wie die meisten 4th Generation Languages) nicht in Konkurrenz zu üblichen Programmiersprachen sondern beschränkt seinen Wirkungsbereich auf mathematische Probleme aller Art, man kann damit beispielsweise keinen Maustreiber programmieren.
Das Dokumentenformat (so genannte "Notebooks") von Mathematica kann zwar mit jedem beliebigen ASCII-Texteditor bearbeitet werden, allerdings bietet sich das nur als Schnittstelle zu automatisierten Prozessen an, d.h. es ist nicht besonders einfach du durchschauen. Wenn ein Notebook graphische Daten (z.B. Diagramme) enthält, werden diese binär codiert (ähnlich UUEncode).
MathCAD wäre ein weiteres Beispiel für ein algebraisches System. Es wird allerdings von einigen Fachleuten bereits zu den 5th Generation Languages gerechnet.
Beispiel Spreadsheets: Microsoft Excel
Spread Sheets sind Tabellenkalkulationsprogramme, die das Arbeiten mit Statistiken und betriebswirtschaftlichen Aufgaben wie Rechnungen und Steuererklärungen erleichtern. Sie sind in zwei Dimensionen aufgebaut (Spalten und Zeilen) und bieten neben einer guten Übersichtlichkeit noch einen meist großen Funktionsumfang zur Erstellung von Auswertungen, Graphiken und automatischen Berechnungen.
Daniel Bricklin, ein Student der Harvard Business School, entwickelte 1978 das erste Spreadsheet-Programm VisiCalc. Es war eine der ersten weit verbreiteten Applikationen, die auf Personal Computern zum Einsatz kam. Es entstand aus dem Bestreben heraus, komplexe Datenmengen anschaulich visuell darzustellen, ohne für jede Aufgabenstellung ein eigenes Programm schreiben zu müssen.
Abbildung 2: VisiCalc (Apple)
Mittlerweile gibt es massenhaft Spreadsheet-Programme (wie Excel, Lotus 1-2-3, Quattro Pro usw.), die in ihrer Funktionalität nicht nur auf simple Summenfunktionen beschränkt sind. Heutzutage haben sie einen reichhaltigen Funktionsumfang von finanzmathematischen Funktionen bis zu Datenbankabfragen und weitreichende Schnittstellen zu anderen Programmen. Außerdem ist zumeist eine Skripting- oder Makrofunktionalität vorhanden.
Am Beispiel von Microsoft Excel werden im folgenden die 4th GL Merkmale von Spreadsheets erklärt:
- Umfangreiches Scripting mit VBA
- Geringer Eingabeaufwand für vergleichsweise komplexe Zusammenhänge
- Allgemeinverständliche visuelle Repräsentation von Zusammenhängen, es kann meist mit einem Blick erkannt werden, worum es geht
- Umfangreiche Diagrammgestaltungsmöglichkeiten
- Zellen können hinsichtlich Format, Schriftart und Farbe hervorgehoben werden (trägt zur Anschaulichkeit bei)
- Exceldokumente können nicht in Texteditoren bearbeitet werden, sie benutzen ein eigenes (nicht-ASCII) Format, das üblicherweise nur von Tabellenkalkulationsprogrammen gelesen werden kann
Wie bei den anderen hier angeführten Beispielen (Mathematica, Visual Basic) ist auch hier die visuelle Komponente stark für die weite Verbreitung ausschlaggebend. Es wird im Gegensatz zu 3GLs auf die hohe Plattformunabhängigkeit zugunsten von besserer Darstellbarkeit verzichtet; auch das ist ein typisches Merkmal von 4GLs, sie richten sich also nicht nach einer möglichst breit gestreuten Bandbreite von Benutzern / Plattformen / Systemen, sondern liefern sehr spezielle Verfahren zur Lösung von spezifischen Problemen.
Beispiel Application Builders: Visual Basic
Eine weitere Form von 4th Generation Languages sind so genannte "Application Builders", die eine visuelle Oberfläche zur Erzeugung von Programmen bieten. Sie stellen Werkzeuge zur verfügen, mit denen graphische Applikation erzeugt werden, ohne dass der Programmierer selbst Code schreiben muss.
Die Motivation dafür ist offensichtlich: Früher konnten Programme mit graphischer Benutzeroberfläche (GUI – Graphical User Interface) nur so erzeugt werden, indem man sie mit API-Befehlen auf dem Bildschirm positioniert und dabei viel herumrechnen musste, was einerseits sehr unintuitiv und andererseits äußerst fehleranfällig war. Es lag also nahe, eine "GUI für GUI-Entwicklung" zur Verfügung zu stellen. Nach dem WYSIWYG (What You See Is What You Get) Prinzip werden Fensterlayout und Bedienungselemente wie Buttons oder Textfelder auf dem Bildschirm angezeigt. Die Ergebnisse wirken meist professioneller und durchdachter als wenn man die Fenster händisch verteilt.
Die Vorteile sind offensichtlich:
- bessere Gestaltungsmöglichkeiten
- weniger Implementierungsaufwand
- einfachere Entwicklung
- Arbeitserleichterung für sich wiederholende Aufgabenstellungen
- GUI-Objekte können über Property-Fenster in ihren Eigenschaften nachträglich geändert werden, ohne dass der Source Code bearbeitet werden muss
Ein wichtiger Punkt ist außerdem, dass die mit solchen Application Builders erstellten Programme meist in eine Programmiersprache übersetzt werden. Üblicherweise kann das erzeugte Format auch nachträglich von den visuellen Editoren wieder geöffnet werden, hierbei ist es essentiell, dass ein Mittelweg aus "human" und "machine readable" gefunden wird.
Für viele Programmiersprachen gibt es mittlerweile Application Builder auf verschiedenen Plattformen. Diese sind üblicherweise (wie bei fast allen 4GLs und im Gegensatz zu den meisten 3GLs) kommerzielle Anwendungen, deren Entwicklung und Support einer Firma obliegt. Meistens sind sie außerdem nicht von nationalen/internationalen Standardisierungsstellen genormt.
Einige Beispiele:
- Borland Delphi
- Microsoft Visual Basic / C++
- Qt Designer
Ein weiterer Aspekt sind die so genannten "Wizards", eigentlich Expertensysteme, die ihrerseits Forms oder Programmprojekte automatisch erstellen.
Weitere Beispiele
Es gibt noch viele weitere Beispiele für 4GLs. Diese sind meistens selbst Applikationen mit GUI:
- Graphik-Editoren:
legen eine absolut notwendige Abstraktionsebene zwischen den Benutzer und die binäre Darstellung von Bildern; es ist für die Erstellung von Vektor-Graphiken eine Programmierung noch einigermaßen vorstellbar, aber die Programmierung von Bitmaps ist ohne deren Hilfe kaum möglich - "Intelligente"
Text-Editoren (Programmier-Tools):
hier sind Emacs und die "Intellisense"-Technologie von Visual Studio zu erwähnen; sie analysieren den Text und heben verschiedene Sprachelemente farblich hervor
Objektorientierte Sprachen | Skriptsprachen | Ada und Pascal | Cobol und Algol | 4th Generation Languages